《Kubernetes权威指南:从Docker到Kubernetes实践全接触》读书笔记
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
写在前面
- 之前简单的了解过,但是机器的原因,只有单机,因为安装Docker的原因,本机VM上的红帽节点起不来了。懂得不多,视频上都是多节点的,所以教学视屏上的所以Demo没法搞。
- 前些时间公司的一个用K8s搞得项目要做安全测试,结果连服务也停不了。很无力。所以刷这本书,系统学习下。
- 博客主要是读书笔记。在更新。。。。。。
- 书很不错,有条件的小伙伴可以支持作者一波
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
第1章Kubernetes入门
1.1 Kubernetes是什么?
首先,它是一个全新的基于容器技术的分布式架构领先方案。这个方案虽然还很新,但它是谷歌十几年以来大规模应用容器技术的经验积累和升华的一个重要成果。
使用Kubernetes提供的解决方案,我们不仅节省了不少于30%的开发成本,同时可以将精力更加集中于业务本身,而且由于Kubernetes提供了强大的自动化机制,所以系统后期的运维难度和运维成本大幅度降低。
Kubermetes平台对现有的编程语言、编程框架、中间件没有任何侵入性,因此现有的系统也很容易改造升级并迁移到Kubernetes平台上。
最后, Kubermetes是一个完备的分布式系统支撑平台。Kubernetes具有完备的集群管理能力,包括多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和服务发现机制、内建智能负载均衡器、强大的故障发现和自我修复能力、服务滚动升级和在线扩容能力、可扩展的资源自动调度机制,以及多粒度的资源配额管理能力。
Kubermetes提供了完善的管理工具,这些工具涵盖了包括开发、部署测试、运维监控在内的各个环节
Kubernetes是一个全新的基于容器技术的分布式架构解决方案,并且是一个一站式的完备的分布式系统开发和支撑平台。
Kubermetes的一些基本知识,在Kubermetes 中, Service (服务)是分布式集群架构的核心,一个Service对象拥有如下关键特征。
| 关键特征 |
|---|
| 拥有一个唯一指定的名字(比如mysgq-server). |
| 拥有一个虚拟IP (Cluster IP, Service IP或VIP)和端口号。 |
| 能够提供某种远程服务能力。 |
| 被映射到了提供这种服务能力的一组容器应用上。 |
Kubemetes能够让我们通过Service (虚拟Cluster IP +Service Port)连接到指定的Service上。有了Kubernetes内建的透明负载均衡和故障恢复机制,不管后端有多少服务进程,也不管某个服务进程是否会由于发生故障而重新部署到其他机器,都不会影响到我们对服务的正常调用。
容器提供了强大的隔离功能,所以有必要把为 Service 提供服务的这组进程放入容器中进行隔离。为此, Kubemetes 设计了Pod 对象,将每个服务进程包装到相应的Pod中,使其成为 Pod中运行的一个容器( Container )。
为了建立 Service &&Pod 间的关联关系, Kubemetes 首先给每Pod 贴上 个标签(Label),类似于html中,给元素定义属性。然后给相应的 Service 定义标签选择器( Label Selector ),比如 MySQL Service 的标签选择器的选择条件为 name=mysql ,意为该 Service 要作用于所有包含 name=mysql的
Label Pod 这样 来,就巧妙地解决了 Service Pod 的关联问题
到
Pod,我们这里先简单说说其概念:
| Pod概念 |
|---|
Pod 运行在一个我们称之为节点(Node)的环境中,这个节点既可以是物理机,也可以是私有云或者公有云中的虚拟机,通常在一个节点上运行几百个 Pod : |
每个 Pod 里运行着 个特殊的被称之为 Pause 的容器,其他容器则为业务容器,这些业务容器共享 Pause 容器的网络栈和 Volume 挂载卷因此它们之间的通信和数据交换更为高效,在设计时我们可以充分利用这特性将一组密切相关的服务进程放入同一 Pod 中。 |
| 并不是每个 Pod 和它里面运行的容器都能“映射”到Service 上,只有那些提供服务(无论是对内还是对外)的 Pod 才会被“映射”成服务。 |
在
集群管理方面, Kubemetes 将集群中的机器划分为Master节点和一群工作节点(Node)
| 集群管理 |
|---|
在 Master 节点上运行着集群管理相关的组进程 kube-apiserver ,kube-controller-manager,kube-scheduler ,这些进程实现了整个集群的资源管理、 Pod 调度、弹性伸缩、安全控制、系统监控和纠错等管理功能,且都是全自动完成的。 |
Node 作为集群中的工作节点,运行真正的应用程序,在 Node上 Kubemetes 管理的最小运行单元是 Pod ,Node 上运行着 Kubemetes的kubelet, kube-proxy 服务进程,这些服务进程负责 Pod 的创建、启动、监控、重启、销毁,以及实现软件模式的负载均衡器。 |
传统的 IT 系统中
服务扩容和服务升级这两个难题在k8s中的解决
Kubemetes 集群中,你只需为需要扩容的 Service 关联的 Pod 创建一个 RC(Replication Conoiler ),则该 Service 的扩容以至于后来的 Service 升级等头疼问题都迎刃而解 .
RC定义文件中包括以下 3 个关键信息。
| RC定义文件 |
|---|
| 目标 Pod 的定义 |
| 目标 Pod 需要运行的副本数量(Replicas )。 |
| 要监控的目标 Pod 的标签( Label) |
在创建好RC (系统将自动创建好Pod)后, Kubernetes会通过RC中定义的Label筛选出对应的Pod实例并实时监控其状态和数量,如果实例数量少于定义的副本数量(Replicas),则·会根据RC中定义的Pod模板来创建一个新的Pod,然后将此Pod调度到合适的Node上启动运行,直到Pod实例的数量达到预定目标。这个过程完全是自动化的,. 服务的扩容就变成了一个纯粹的简单数字游戏了,只要修改 RC 中的副本数量即可。后续的Service 升级也将通过修改 RC 来自动完成。
1.2 为什么要用 Kubernetes
使用 Kubemetes 的理由很多,最根本的一个理由就是: IT 从来都是 个由新技术驱动的行业。
Kubemetes 作为当前唯一被业界广泛认可和看好的Docker 分布式系统解决方案,
使用了 Kubemetes 又会收获哪些好处呢?
| Kubemetes好處 |
|---|
| 在采用Kubemetes 解决方案之后,只需个1精悍的小团队就能轻松应对 |
| 使用 Kubemetes 就是在全面拥抱微服务架构。微服务架构的核心是将 个巨大的单体应用分解为很多小的互相连接的微服务,一个微服务背后可能有多个实例副本在支撑,副本的数量可能会随着系统的负荷变化而进行调整,内嵌的负载均衡器在这里发挥了重要作用 |
| 系统可以随时随地整体“搬迁”到公有云上。 |
Kubemetes 系统架构具备了超强的横向扩容能力。利用 ubemetes 提供的工具,甚至可以在线完成集群扩容 只要我们的微服务设计得好,结合硬件或者公有云资源的线性增加,系统就能够承受大 用户并发访问所带来的巨大压力。 |
1.3 从一个简单的例子开始
Java Web 应用的结构比较简单,是一个运行在 Tomcat 里的 Web App。
此应用需要启动两个容器: Web App容器和MySQL容器,并且Web App容器需要访问MySQL容器。
在Docker时代,假设我们在一个宿主机上启动了这两个容器,
则我们需要把MySQL容器的IP地址通过环境变量的方式注入Web App容器里;同时,需要将Web App容器的8080端口映射到宿主机的8080端口,以便能在外部访问。
在Kubernetes时代是如何完成这个目标的。
1.3.1环境准备
1 | # 关闭CentoS自带的防火墙服务: |
至此,一个单机版的Kubernetes集群环境就安装启动完成了。接下来,我们可以在这个单机版的Kubernetes集群中上手练习了。
书里镜像相关地址: https://hub.docker.com/u/kubeguide/.
1.3.2启动MySQL服务
首先为MySQL服务创建一个
RC定义文件:mysql-rc.yaml,文件的完整内容和解释;
1 | apiVersion: v1 |

yaml定义文件中
yaml定义文件 |
|---|
kind属性,用来表明此资源对象的类型,比如这里的值为”ReplicationController”,表示这是一个RC: |
spec一节中是RC的相关属性定义,比如spec.selector是RC的Pod标签(Label)选择器,即监控和管理拥有这些标签的Pod实例,确保当前集群上始终有且仅有replicas个Pod实例在运行,这里我们设置replicas=1表示只能运行一个MySQL Pod实例。 |
当集群中运行的Pod数量小于replicas时, RC会根据spec.template一节中定义的Pod模板来生成一个新的Pod实例, spec.template.metadata.labels指定了该Pod的标签. |
需要特别注意的是:这里的labels必须匹配之前的spec.selector,否则此RC每次创建了一个无法匹配Label的Pod,就会不停地尝试创建新的Pod。 |
1 | [root@liruilong k8s]# kubectl create -f mysql-rc.yaml |
嗯,这里刚开始搞得的时候是有问题的,
pod一直没办法创建成功,第一次启动容器时,STATUS一直显示CONTAINERCREATING,我用的是阿里云ESC单核2G+40G云盘,我最开始以为系统核数的问题,因为看其他的教程写的需要双核,但是后来发现不是,网上找了解决办法,一顿操作猛如虎,后来不知道怎么就好了。
- 有说基础镜像外网拉不了,只能用 docker Hub的,有说 ,权限的问题,还有说少包的问题,反正都试了,这里列出几个靠谱的解决方案
K8s 根据mysqlde RC的定义自动创建的Pod。由于Pod的调度和创建需要花费一定的时间,比如需要一定的时间来确定调度到哪个节点上,以及下载Pod里容器的镜像需要一段时间,所以一开始我们看到Pod的状态将显示为Pending。当Pod成功创建完成以后,状态最终会被更新为Running我们通过docker ps指令查看正在运行的容器,发现提供MySQL服务的Pod容器已经创建并正常运行了,此外,你会发现MySQL Pod对应的容器还多创建了一个来自谷歌的pause容器,这就是Pod的“根容器".
我们创建一个与之关联的Kubernetes Service 的定义文件 mysql-sve.yaml
1 | apiVersion: v1 |
我们通过kubectl create命令创建Service对象。运行kubectl命令:
1 | [root@liruilong k8s]# kubectl create -f mysql-svc.yaml |
注意到MySQL服务被分配了一个值为10.254.155.86的Cluster IP地址,这是一个虚地址,随后, Kubernetes集群中其他新创建的Pod就可以通过Service的Cluster IP+端口号3306来连接和访问它了。
在通常情况下, Cluster IP是在Service创建后由Kubernetes系统自动分配的,其他Pod无法预先知道某个Service的Cluster IP地址,因此需要一个服务发现机制来找到这个服务。
为此,最初时, Kubernetes巧妙地使用了Linux环境变量(Environment Variable)来解决这个问题,后面会详细说明其机制。现在我们只需知道,根据Service的唯一名字,容器可以从环境变量中获取到Service对应的Cluster IP地址和端口,从而发起TCP/IP连接请求了。
1.3.3启动Tomcat应用
创建对应的 RC 文件 myweb-rc.yaml
1 | apiVersion: v1 |

1 | [root@liruilong k8s]# vim myweb-rc.yaml |
最后,创建对应的 Service 。以下是完整yaml定义文件 myweb-svc.yaml:
1 | apiVersion: v1 |

1 | [root@liruilong k8s]# vim myweb-svc.yaml |
1.3.4通过浏览器访问网页
1 | [root@liruilong k8s]# curl http://127.0.0.1:30001/demo/ |
数据库连接有问题,这里百度发现是mysql驱动版本问题
1 | [root@liruilong k8s]# docker logs a05d16ec69ff |
1 | apiVersion: v1 |
1 | [root@liruilong k8s]# kubectl delete -f mysql-rc.yaml |
1 | Digest: sha256:7cf2e7d7ff876f93c8601406a5aa17484e6623875e64e7acc71432ad8e0a3d7e |
1 |
|
1.4 Kubernetes基本概念和术语
Kubernetes中的大部分概念如Node, Pod,Replication Controller, Service等都可以看作一种“资源对象”,几乎所有的资源对象都可以通过Kubernetes提供的kubect工具(或者API编程调用)执行增、删、改、查等操作并将其保存在etcd中持久化存储。从这个角度来看, Kubernetes其实是一个高度自动化的资源控制系统,它通过跟踪对比etcd库里保存的“资源期望状态”与当前环境中的“实际资源状态”的差异来实现自动控制和自动纠错的高级功能。
Kubernetes集群的两种管理角色:
Master和Node.
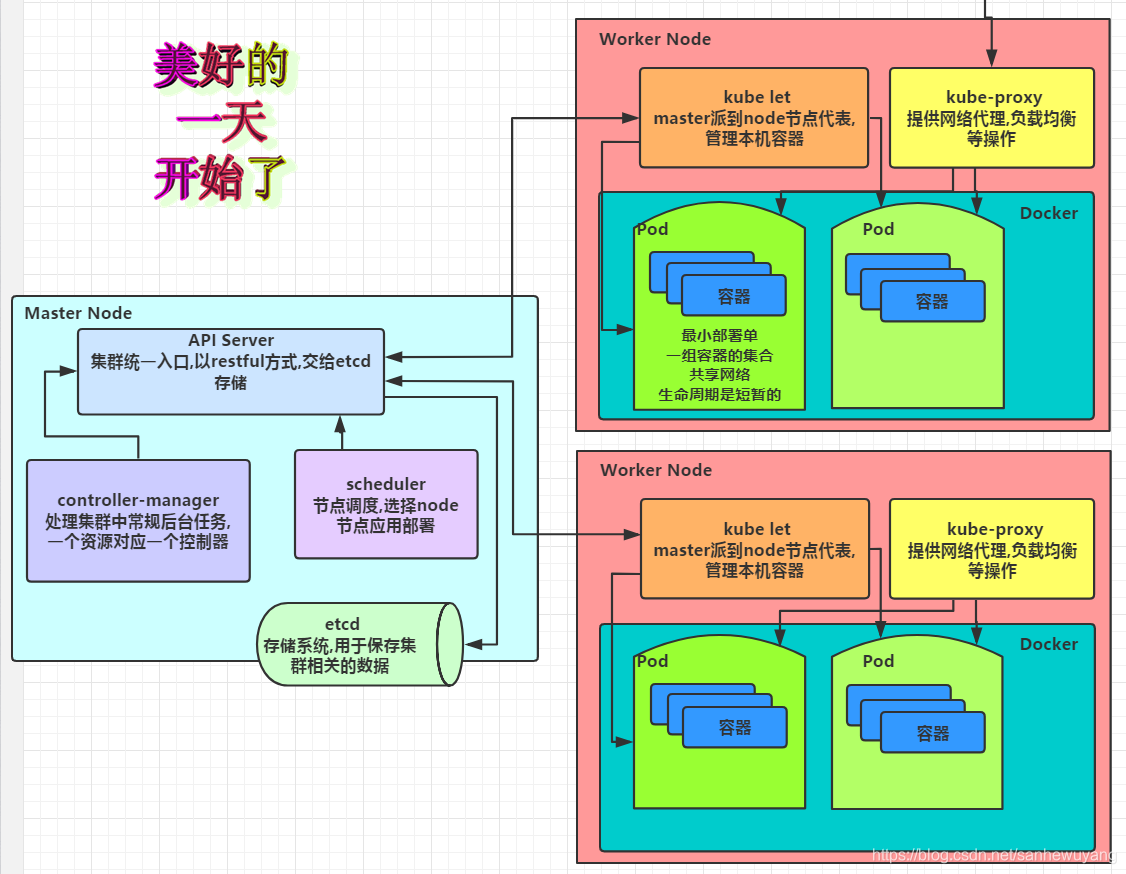
1.4.1 Master
Kubernetes里的Master指的是集群控制节点,每个Kubernetes集群里需要有一个Master节点来负责整个集群的管理和控制,基本上Kubernetes的所有控制命令都发给它,它来负责具体的执行过程,我们后面执行的所有命令基本都是在Master节点上运行的。
Master节点通常会占据一个独立的服务器(高可用部署建议用3台服务器),其主要原因是它太重要了,是整个集群的“首脑”,如果宕机或者不可用,那么对集群内容器应用的管理都将失效。Master节点上运行着以下一组关键进程。
| Master节点上关键进程 |
|---|
Kubernetes API Server (kube-apiserver):提供了HTTP Rest接口的关键服务进程,是Kubernetes里所有资源的增、删、改、查等操作的唯一入口,也是集群控制的入口进程。 |
Kubernetes Controller Manager (kube-controller-manager): Kubernetes里所有资源对象的自动化控制中心,可以理解为资源对象的“大总管”。 |
Kubernetes Scheduler (kube-scheduler):负责资源调度(Pod调度)的进程,相当于公交公司的“调度室”。 |
另外,在Master节点上还需要启动一个etcd服务,因为Kubernetes里的所有资源对象的数据全部是保存在etcd中的。 |
除了Master, Kubernetes集群中的其他机器被称为Node节点
总结一下,我们要操作k8s,在管理节点那我们怎么操作,我们通过kube-apiserver来接受用户的请求,通过kubu-scheduler来负责资源的调度,是使用work1计算节点来处理还是使用work2计算节点来处理,然后在每个节点上要运行一个代理服务kubelet,用来控制每个节点的操作,但是每个节点的状态,是否健康我们不知道,这里我们需要kube-controller-manager
1.4.2 Node
在较早的版本中也被称为Miniono与Master一样, Node节点可以是一台物理主机,也可以是一台虚拟机。 Node节点才是Kubermetes集群中的工作负载节点,每个Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机时,其上的工作负载会被Master自动转移到其他节点上去。 每个Node节点上都运行着以下一组关键进程。
| 每个Node节点上都运行关键进程 |
|---|
kubelet:负责Pod对应的容器的创建、启停等任务,同时与Master节点密切协作,实现集群管理的基本功能。 |
kube-proxy:实现Kubernetes Service的通信与负载均衡机制的重要组件。) |
Docker Engine (docker): Docker引擎,负责本机的容器创建和管理工作。 |
Node节点可以在运行期间动态增加到Kubernetes集群中,前提是这个节点上已经正确安装、配置和启动了上述关键进程,**在默认情况下kubelet会向Master注册自己,这也是Kubernetes推荐的Node管理方式**。
一旦Node被纳入集群管理范围, kubelet进程就会定时向Master节点汇报自身的情报,例如操作系统、Docker版本、机器的CPU和内存情况,以及当前有哪些Pod在运行等,这样Master可以获知每个Node的资源使用情况,并实现高效均衡的资源调度策略。而某个Node超过指定时间不上报信息时,会被Master判定为“失联", Node的状态被标记为不可用(Not Ready),随后Master会触发“工作负载大转移”的自动流程。
查看集群中的Node节点和节点的详细信息
1 | [root@liruilong k8s]# kubectl get nodes |
1.4.3 Pod
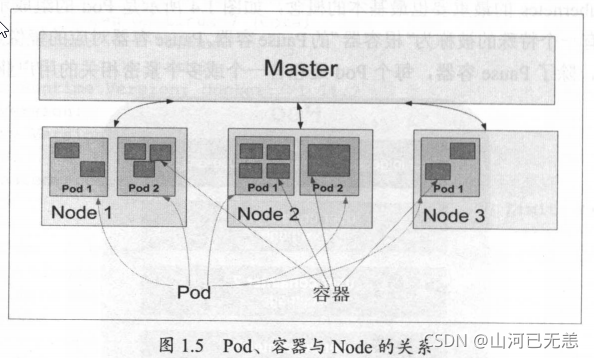
Pod是Kubernetes的最重要也最基本的概念,

每个Pod都有一个特殊的被称为“根容器”的Pause容器。Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器,每个Pod还包含一个或多个紧密相关的用户业务容器。
为什么Kubernetes会设计出一个全新的Pod的概念并且Pod有这样特殊的组成结构? |
|---|
原因之一:在一组容器作为一个单元的情况下,我们难以对“整体”简单地进行判断及有效地进行行动。引入业务无关并且不易死亡的Pause容器作为Pod的根容器,以它的状态代表整个容器组的状态,就简单、巧妙地解决了这个难题。 |
原因之二: Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂接的Volume,这样既简化了密切关联的业务容器之间的通信问题,也很好地解决了它们之间的文件共享问题。 |
Kubernetes 为每个Pod都分配了唯一的IP地址,称之为Pod IP,一个Pod里的多个容器共享Pod IP地址。 Kuberetes要求底层网络支持集群内任意两个Pod之间的TCP/P直接通信,这通常采用虚拟二层网络技术来实现(网桥),
在
Kubernetes里,一个Pod里的容器与另外主机上的Pod容器能够直接通信。
Pod其实有两种类型:普通的Pod及静态Pod (Static Pod)
| Pod两种类型 | 描述 |
|---|---|
静态Pod (Static Pod) |
并不存放在Kubernetes的etcd存储里,而是存放在某个具体的Node上的一个具体文件中,并且只在此Node上启动运行。 |
普通的Pod |
一旦被创建,就会被放入到etcd中存储,随后会被Kubernetes Masten调度到某个具体的Node上并进行绑定(Binding),随后该Pod被对应的Node上的kubelet进程实例化成一组相关的Docker容器并启动起来。 |
在默认情况下,当
Pod里的某个容器停止时,Kubernetes会自动检测到这个问题并且重新启动这个Pod(重启Pod里的所有容器),如果Pod所在的Node宕机,则会将这个Node上的所有Pod重新调度到其他节点上.
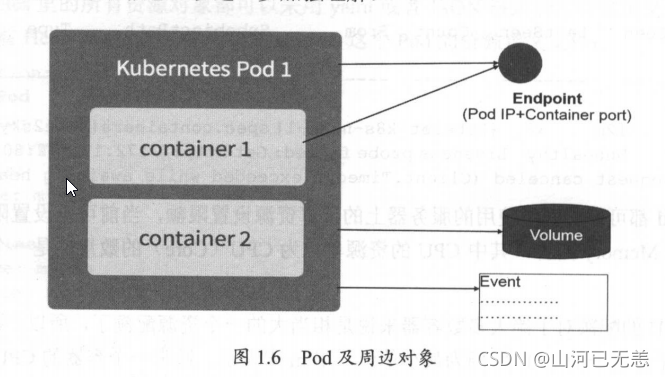
Kubernetes里的所有资源对象都可以采用yaml或者JSON格式的文件来定义或描述,下面是我们在之前Hello World例子里用到的myweb这个Pod的资源定义文件:
1 | apiVersion: v1 |
Kubernetes的Event概念, Event是一个事件的记录,记录了事件的最早产生时间、最后重现时间、重复次数、发起者、类型,以及导致此事件的原因等众多信息。Event通常会关联到某个具体的资源对象上,是排查故障的重要参考信息,
Pod同样有Event记录,当我们发现某个Pod迟迟无法创建时,可以用kubectl describe pod xxxx来查看它的描述信息,用来定位问题的原因
在Kubernetes里,一个计算资源进行配额限定需要设定以下两个参数。
| 计算资源进行配额限定 |
|---|
| Requests:该资源的最小申请量,系统必须满足要求。 |
| Limits:该资源最大允许使用的量,不能被突破,当容器试图使用超过这个量的资源时,可能会被Kubernetes Kill并重启。 |
通常我们会把Request设置为一个比较小的数值,符合容器平时的工作负载情况下的资源需求,而把Limit设置为峰值负载情况下资源占用的最大量。
比如下面这段定义,表明MysQL容器申请最少0.25个CPU及64MiB内存,在运行过程中MySQL容器所能使用的资源配额为0.5个CPU及128MiB内存:
1 | .... |
Pod Pod 周边对象的示意图
1.4.4 Lable 标签
Label是Kubernetes系统中另外一个核心概念。一个Label是一个key-value的键值对。其中key与value由用户自己指定。
Label可以附加到各种资源对象上,例如Node、Pod、Service、RC等,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象上去, Label通常在资源对象定义时确定,也可以在对象创建后动态添加,或者删除。
可以通过给指定的资源对象捆绑一个或多个不同的Label来实现多维度的资源分组管理功能,以便于灵活、方便地进行资源分配、调度、配置、部署等管理工作。
例如:部署不同版本的应用到不同的环境中;或者监控和分析应用(日志记录、监控、告警)等。一些常用的Label示例如下。
1 | 版本标签: "release" : "stable", "release":"canary".... |
可以通过多个Label Selector表达式的组合实现复杂的条件选择,多个表达式之间用“,”进行分隔即可,几个条件之间是“AND”的关系,即同时满足多个条件,比如下面的例子:
1 | name=标签名 |
1 | apiVersion: v1 |
新出现的管理对象如Deployment, ReplicaSet, DaemonSet和Job则可以在Selector中使用基于集合的筛选条件定义,例如:
1 | selector: |
matchLabels用于定义一组Label,与直接写在Selector中作用相同; matchExpressions用于定义一组基于集合的筛选条件,可用的条件运算符包括: In, NotIn, Exists和DoesNotExist.
如果同时设置了matchLabels和matchExpressions,则两组条件为"AND"关系,即所有条件需要同时满足才能完成Selector的筛选。
Label Selector在Kubernetes中的重要使用场景有以下几处:
kube-controller进程通过资源对象RC上定义的Label Selector来筛选要监控的Pod副本的数量,从而实现Pod副本的数量始终符合预期设定的全自动控制流程
kube-proxy进程通过Service的Label Selector来选择对应的Pod, 自动建立起每个Service到对应Pod的请求转发路由表,从而实现Service的智能负载均衡机制
通过对某些Node定义特定的Label,并且在Pod定义文件中使用NodeSelector这种标签调度策略, kube-scheduler进程可以实现Pod “定向调度”的特性。
1.4.5 Replication Controller
RC是Kubernetes系统中的核心概念之一,简单来说,它其实是定义了一个期望的场景,即声明某种Pod的副本数量在任意时刻都符合某个预期值,所以RC的定义包括如下几个部分。
| RC |
|---|
Pod 期待的副本数(replicas) |
用于筛选目标Pod的Label Selector |
当Pod的副本数量小于预期数量时,用于创建新Pod的Pod模板(template)。 |
下面是一个完整的RC定义的例子,即确保拥有tier-frontend标签的这个Pod (运行Tomcat容器)在整个Kubernetes集群中始终只有一个副本:
1 | apiVersion: v1 |
当我们定义了一个RC并提交到Kubernetes集群中以后, Master节点上的Controller Manager组件就得到通知,定期巡检系统中当前存活的目标Pod,并确保目标Pod实例的数量刚好等于此RC的期望值,如果有过多的Pod副本在运行,系统就会停掉一些Pod,否则系统就会再自动创建一些Pod,
通过RC, Kubernetes实现了用户应用集群的高可用性,并且大大减少了系统管理员在传统IT环境中需要完成的许多手工运维工作(如主机监控脚本、应用监控脚本、故障恢复脚本等)
下面我们以3个Node节点的集群为例,说明Kubernetes如何通过RC来实现Pod副本数量自动控制的机制。假如我们的RC里定义redis-slave这个Pod需要保持3个副本,系统将可能在其中的两个Node上创建Pod,图1.9描述了在两个Node上创建redis-slave Pod的情形。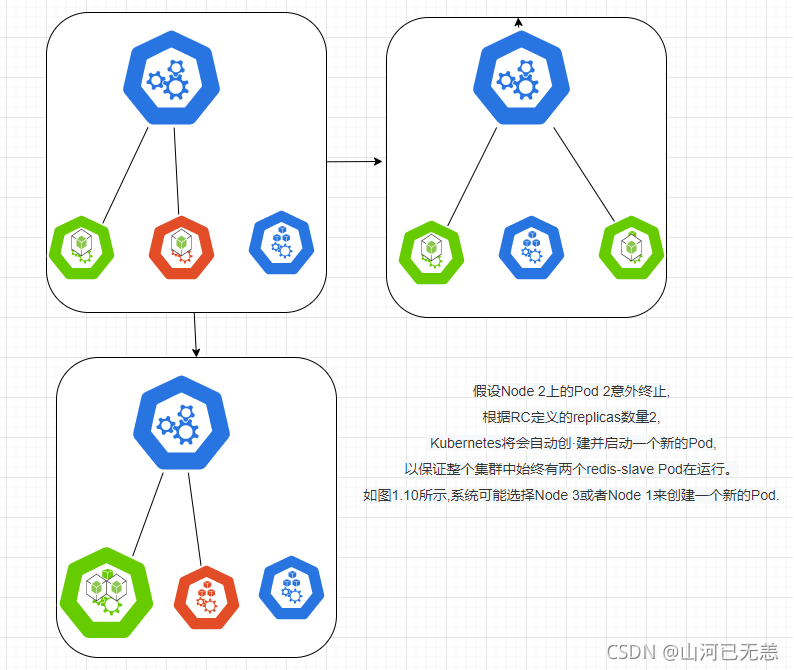
在运行时,我们可以通过 修改RC的副本数量,来实现Pod的动态缩放(Scaling)功能,这可以通过执行kubectl scale命令来一键完成:
1 | kubectl scale rc redsi-slave --replicas=3 |
需要注意的是,删除RC并不会影响通过该RC已创建好的Pod,为了删除所有Pod,可以设置replicas的值为0,然后更新该RC。另外, kubectl提供了stop和delete命令来一次性删除RC和RC控制的全部Pod。
应用升级时,通常会通过Build一个新的Docker镜像,并用新的镜像版本来替代旧的版本的方式达到目的。在系统升级的过程中,我们希望是平滑的方式,比如当前系统中10个对应的旧版本的Pod,最佳的方式是旧版本的Pod每次停止一个,同时创建一个新版本的Pod,在整个升级过程中,此消彼长,而运行中的Pod数量始终是10个,通过RC的机制, Kubernetes很容易就实现了这种高级实用的特性,被称为“滚动升级” (Rolling Update)
1.4.6 Deployment
Deployment是Kubernetes v1.2引入的新概念,引入的目的是为了更好地解决Pod的编排问题。
**Deployment相对于RC的一个最大升级是我们可以随时知道当前Pod “部署”的进度**。实际上由于一个Pod的创建、调度、绑定节点及在目标Node上启动对应的容器这一完整过程需要一定的时间,所以我们期待系统启动N个Pod副本的目标状态,实际上是一个连续变化的“部署过程”导致的最终状态。
Deployment的典型使用场景有以下几个。
| Deployment的典型使用场景 |
|---|
| 创建一个Deployment对象来生成对应的Replica Set并完成Pod副本的创建过程。 |
| 检查Deployment的状态来看部署动作是否完成(Pod副本的数量是否达到预期的值) |
| 更新Deployment以创++建新的Pod (比如镜像升级)。 |
| 如果当前Deployment不稳定,则回滚到一个早先的Deployment版本。 |
| 暂停Deployment以便于一次性修改多个PodTemplateSpec的配置项,之后再恢复Deployment,进行新的发布。 |
| 扩展Deployment以应对高负载。 |
| 查看Deployment的状态,以此作为发布是否成功的指标。 |
| 清理不再需要的旧版本ReplicaSets。 |
Deployment的定义与Replica Set的定义很类似,除了API声明与Kind类型等有所区别:
1 | apiversion: extensions/vlbetal apiversion: v1 |
创建一个 tomcat-deployment.yaml Deployment 描述文件:
1 | apiVersion: extensions/v1betal |
运行如下命令创建 Deployment:
1 | kubectl create -f tomcat-deploment.yaml |
对上述输出中涉及的数量解释如下。
| 数量 | 解释 |
|---|---|
| DESIRED | Pod副本数量的期望值,即Deployment里定义的Replica. |
| CURRENT | 当前Replica的值,实际上是Deployment所创建的Replica Set里的Replica值,这个值不断增加,直到达到DESIRED为止,表明整个部署过程完成。 |
| UP-TO-DATE | 最新版本的Pod的副本数量,用于指示在滚动升级的过程中,有多少个Pod副本已经成功升级。 |
| AVAILABLE | 当前集群中可用的Pod副本数量,即集群中当前存活的Pod数量。 |
运行下述命令查看对应的Replica Set,我们看到它的命名与Deployment的名字有关系:
1 | kubectl get rs |
1.4.7 Horizontal Pod Autoscaler
**HPA与之前的RC、 Deployment一样,也属于一种Kubernetes资源对象**。通过 追踪分析RC控制的所有目标Pod的负载变化情况,来确定是否需要针对性地调整目标Pod的副本数,这是HPA的实现原理 。当前, HPA可以有以下两种方式作为Pod负载的度量指标。
| Horizontal Pod Autoscaler |
|---|
| CPUUtilizationPercentage. |
| 应用程序自定义的度量指标,比如服务在每秒内的相应的请求数(TPS或QPS) |
1 | apiversion: autoscaling/v1 |
CPUUtilizationPercentage是一个算术平均值,即目标Pod所有副本自身的CPU利用率的平均值。一个Pod自身的CPU利用率是该Pod当前CPU的使用量除以它的Pod Request的值,比,如我们定义一个Pod的Pod Request为0.4,而当前Pod的CPU使用量为0.2,则它的CPU使用率为50%
根据上面的定义,我们可以知道这个HPA控制的目标对象为一个名叫php-apache Deployment里的Pod副本,当这些Pod副本的CPUUtilizationPercentage的值超过90%时会触发自动动态扩容行为,扩容或缩容时必须满足的一个约束条件是Pod的副本数要介于1与10之间。
除了可以通过直接定义yaml文件并且调用kubectrl create的命令来创建一个HPA资源对象的方式,我们还能通过下面的简单命令行直接创建等价的HPA对象:
1 | kubectl autoscale deployment php-apache --cpu-percent=90--min-1 --max=10 |
1.4.8 StatefulSet
在Kubernetes系统中, Pod的管理对象RC, Deployment, DaemonSet和Job都是面向无状态的服务。 但现实中有很多服务是有状态的,特别是一些复杂的中间件集群,例如MysQL集·群、MongoDB集群、Akka集群、ZooKeeper集群等,这些应用集群有以下一些共同点:
| 共同點 |
|---|
| 每个节点都有固定的身份ID,通过这个ID,集群中的成员可以相互发现并且通信。 |
| 集群的规模是比较固定的,集群规模不能随意变动。 |
| 集群里的每个节点都是有状态的,通常会持久化数据到永久存储中。 |
| 如果磁盘损坏,则集群里的某个节点无法正常运行,集群功能受损 |
如果用
RC/Deployment控制Pod副本数的方式来实现上述有状态的集群,则我们会发现第1点是无法满足的,因为Pod的名字是随机产生的,Pod的IP地址也是在运行期才确定且可能有变动的,我们事先无法为每个Pod确定唯一不变的ID,
为了能够在其他节点上恢复某个失败的节点,这种集群中的Pod需要挂接某种共享存储,为了解决这个问题, Kubernetes从v1.4版本开始引入了PetSet这个新的资源对象,并且在v1.5版本时更名为StatefulSet, StatefulSet从本质上来说,可以看作DeploymentRC的一个特殊变种,它有如下一些特性。)
| 特性 |
|---|
StatefulSet里的每个Pod都有稳定、唯一的网络标识,可以用来发现集群内的其他成员。假设StatefulSet的名字叫kafka,那么第1个Pod 叫 kafka-0,第2个叫kafk-1,以此类推。) |
StatefulSet控制的Pod副本的启停顺序是受控的,操作第n个Pod时,前n-1个Pod已经是运行且准备好的状态) |
StatefulSet里的Pod采用稳定的持久化存储卷,通过PV/PVC来实现,删除Pod时默认不会删除与StatefulSet相关的存储卷(为了保证数据的安全)。 |
statefulSet除了要与PV卷捆绑使用以存储Pod的状态数据,还要与Headless Service配合使用,即在每个StatefulSet的定义中要声明它属于哪个Headless Service. Headless Service与普通Service的关键区别在于,它没有Cluster IP,如果解析Headless Service的DNS域名,则返回的是该Service对应的全部Pod的Endpoint列表。StatefulSet在Headless Service的基础上又为StatefulSet控制的每个Pod实例创建了一个DNS域名,这个域名的格式为:
1 | $(podname).$(headless service name) |
1.4.9 Service (服务)
Service也是Kubernetes里的最核心的资源对象之一, **Kubernetes里的每个Service其实就是我们经常提起的微服务架构中的一个“微服务”,之前我们所说的Pod, RC等资源对象其实都是为这节所说的“服务”-Kubernetes Service作“嫁衣”的。Pod,RC与Service的逻辑关系**。
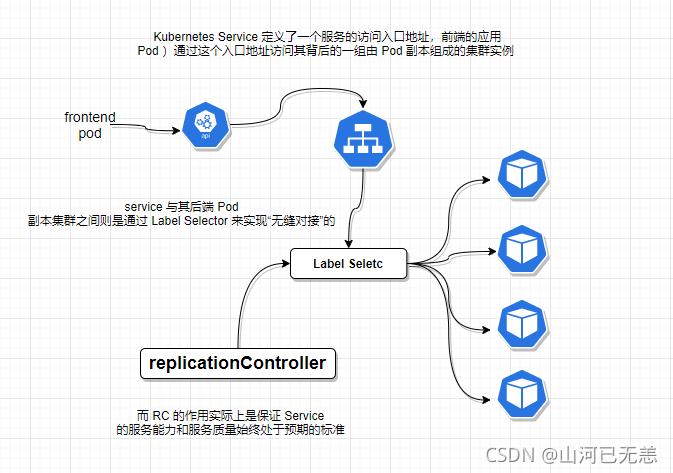
Kubernetes的Service定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口地址访问其背后的一组由Pod副本组成的集群实例, Service与其后端Pod副本集群之间则是通过Label Selector来实现“无缝对接”的。而RC的作用实际上是保证Service的服务能力和服务质量始终处干预期的标准。
每个Pod都会被分配一个单独的IP地址,而且每个Pod都提供了一个独立的Endpoint(Pod IP+ContainerPort)以被客户端访问,现在多个Pod副本组成了一个集群来提供服务.客户端如何来访问它们呢?一般的做法是部署一个负载均衡器(软件或硬件),
**Kubernetes中运行在每个Node上的kube-proxy进程其实就是一个智能的软件负载均衡器,它负责把对Service的请求转发到后端的某个Pod实例上,并在内部实现服务的负载均衡与会话保持机制**。
Kubernetes发明了一种很巧妙又影响深远的设计:
Service不是共用一个负载均衡器的IP地址,而是每个Service分配了一个全局唯一的虚拟IP地址,这个虚拟IP被称为Cluster IP,这样一来,每个服务就变成了具备唯一IP地址的“通信节点”,服务调用就变成了最基础的TCP网络通信问题。
我们知道, Pod的Endpoint地址会随着Pod的销毁和重新创建而发生改变,因为新Pod的IP地址与之前旧Pod的不同。而 **Service一旦被创建, Kubernetes就会自动为它分配一个可用的Cluster IP,而且在Service的整个生命周期内,它的Cluster IP不会发生改变**。于是,服务发现这个棘手的问题在Kubernetes的架构里也得以轻松解决:只要用Service的Name与Service的Cluster IP地址做一个DNS域名映射即可完美解决问题。
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-pod-create] |
Kubernetes Service支持多个Endpoint(端口),**在存在多个Endpoint的情况下,要求每个Endpoint定义一个名字来区分**。下面是Tomcat多端口的Service定义样例:
1 | spec: |
多端口为什么需要给每个端口命名呢?这就涉及Kubernetes的服务发现机制了
Kubernetes 的服务发现机制
| Kubernetes 的服务发现机制 |
|---|
| 最早时Kubernetes采用了Linux环境变量的方式解决这个问题,即每个Service生成一些对应的Linux环境变量(ENV),并在每个Pod的容器在启动时,自动注入这些环境变量 |
| 后来Kubernetes通过Add-On增值包的方式引入了DNS系统,把服务名作为DNS域名,这样一来,程序就可以直接使用服务名来建立通信连接了。目前Kubernetes上的大部分应用都已经采用了DNS这些新兴的服务发现机制 |
外部系统访问 Service 的问题
| Kubernetes里的“三种IP” | 描述 |
|---|---|
| Node IP | Node 节点的IP地址,Node IP是Kubernetes集群中每个节点的物理网卡的IP地址,这是一个真实存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通信,不管它们中是否有部分节点不属于这个Kubernetes集群。**这也表明了Kubernetes集群之外的节点访问Kubernetes集群之内的某个节点或者TCP/IP服务时,必须要通过Node IP进行通信**。 |
| Pod IP | Pod 的 IP 地址:Pod IP是每个Pod的IP地址,它是Docker Engine根据dockero网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,前面我们说过, Kubernetes要求位于不同Node上的Pod能够彼此直接通信,所以Kubernetes里一个Pod里的容器访问另外一个Pod里的容器,就是通过Pod IP所在的虚拟二层网络进行通信的,而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出的。 |
| Cluster IP | Service 的IP地址,Cluster IP仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配IP地址(来源于Cluster IP地址池)。Cluster IP无法被Ping,因为没有一个“实体网络对象”来响应。Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备TCPIP通信的基础,并且它们属于Kubernetes集群这样一个封闭的空间,集群之外的节点如果要访问这个通信端口,则需要做一些额外的工作。在Kubernetes集群之内, Node IP网、Pod IP网与Cluster IP网之间的通信,采用的是Kubermetes自己设计的一种编程方式的特殊的路由规则,与我们所熟知的IP路由有很大的不同。 |
外部系统访问 Service,采用NodePort是解决上述问题的最直接、最有效、最常用的做法。具体做法如下,以tomcat-service为例,我们在Service的定义里做如下扩展即可:
1 | ... |
即这里我们可以通过nodePort:31002 来访问Service,NodePort的实现方式是在Kubernetes集群里的每个Node上为需要外部访问的Service开启个对应的TCP监听端口,外部系统只要用任意一个Node的IP地址+具体的NodePort端口即可访问此服务,在任意Node上运行netstat命令,我们就可以看到有NodePort端口被监听:
Service 负载均衡问题
但NodePort还没有完全解决外部访问Service的所有问题,比如负载均衡问题,假如我们的集群中有10个Node,则此时最好有一个负载均衡器,外部的请求只需访问此负载均衡器的IP地址,由负载均衡器负责转发流量到后面某个Node的NodePort上。如图
| NodePort的负载均衡 |
|---|
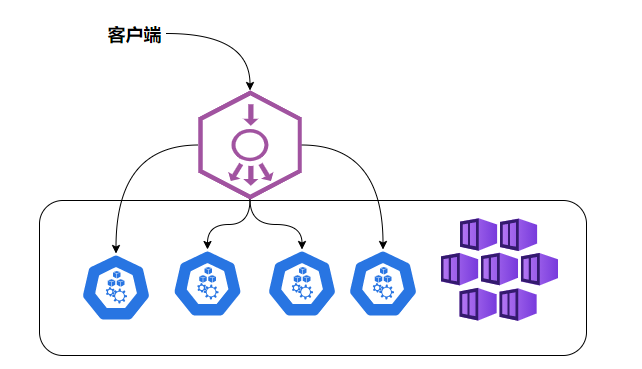 |
Load balancer组件独立于Kubernetes集群之外,通常是一个硬件的负载均衡器,或者是以软件方式实现的,例如HAProxy或者Nginx。对于每个Service,我们通常需要配置一个对应的Load balancer实例来转发流量到后端的Node上 |
Kubernetes提供了自动化的解决方案,如果我们的集群运行在谷歌的GCE公有云上,那么只要我们把Service的type-NodePort改为type-LoadBalancer,此时Kubernetes会自动创建一个对应的Load balancer实例并返回它的IP地址供外部客户端使用。 |
10 Volume (存储卷)
Volume是Pod中能够被多个容器访问的共享目录。Kuberetes的Volume概念、用途和目的与Docker的Volume比较类似,但两者不能等价。
| Volume (存储卷) |
|---|
Kubernetes中的Volume定义在Pod上,然后被一个Pod里的多个容器挂载到具体的文件目录下; |
Kubernetes中的Volume与Pod的生命周期相同,但与容器的生命周期不相关,当容器终止或者重启时, Volume中的数据也不会丢失。 |
Kubernetes支持多种类型的Volume,例如GlusterFS, Ceph等先进的分布式文件系统。 |
Volume的使用也比较简单,在大多数情况下,我们先在Pod上声明一个Volume,然后在容器里引用该Volume并Mount到容器里的某个目录上。举例来说,我们要给之前的Tomcat Pod增加一个名字为datavol的Volume,并且Mount到容器的/mydata-data目录上,则只要对Pod的定义文件做如下修正即可(注意黑体字部分):
1 | template: |
除了可以让一个
Pod里的多个容器共享文件、让容器的数据写到宿主机的磁盘上或者写文件到网络存储中,Kubernetes的Volume还扩展出了一种非常有实用价值的功能,即
容器配置文件集中化定义与管理,这是通过ConfigMap这个新的资源对象来实现的.
Kubernetes提供了非常丰富的Volume类型,下面逐一进行说明。
1. emptyDir
**一个emptyDir Volume是在Pod分配到Node时创建的**。从它的名称就可以看出,它的初始内容为空,并且无须指定宿主机上对应的目录文件,因为这是 Kubernetes自动分配的一个目录,当Pod从Node上移除时, emptyDir中的数据也会被永久删除。emptyDir的一些用途如下。
| emptyDir的一些用途 |
|---|
| 临时空间,例如用于某些应用程序运行时所需的临时目录,且无须永久保留。 |
| 长时间任务的中间过程CheckPoint的临时保存目录。 |
| 一个容器需要从另一个容器中获取数据的目录(多容器共享目录) |
2. hostPath
hostPath为在Pod上挂载宿主机上的文件或目录,它通常可以用于以下几方面。
|容器应用程序生成的日志文件需要永久保存时,可以使用宿主机的高速文件系统进行存储。|
需要访问宿主机上Docker引擎内部数据结构的容器应用时,可以通过定义hostPath为宿主机/var/lib/docker目录,使容器内部应用可以直接访问Docker的文件系统。
在使用这种类型的Volume时,需要注意以下几点。
在不同的Node上具有相同配置的Pod可能会因为宿主机上的目录和文件不同而导致对Volume上目录和文件的访问结果不一致。)
如果使用了资源配额管理,则Kubernetes无法将hostPath在宿主机上使用的资源纳入管理。在下面的例子中使用宿主机的/data目录定义了一个hostPath类型的Volume:
1 | volumes: |
3. gcePersistentDisk
使用这种类型的Volume表示使用谷歌公有云提供的永久磁盘(PersistentDisk, PD)存放Volume的数据,它与emptyDir不同, PD上的内容会被永久存,当Pod被删除时, PD只是被卸载(Unmount),但不会被删除。需要注意是,你需要先创建一个永久磁盘(PD),才能使用gcePersistentDisk.
4. awsElasticBlockStore
与GCE类似,该类型的Volume使用亚马逊公有云提供的EBS Volume存储数据,需要先创建一个EBS Volume才能使用awsElasticBlockStore.
5. NFS
使用NFS网络文件系统提供的共享目录存储数据时,我们需要在系统中部署一个NFSServer,定义NES类型的Volume的示例如下yum -y install nfs-utils
1 | ... |
1.4.11 Persistent Volume
Volume是定义在Pod上的,属于“计算资源”的一部分,而实际上, “网络存储”是相对独立于“计算资源”而存在的一种实体资源。比如在使用虚拟机的情况下,我们通常会先定义一个网络存储,然后从中划出一个“网盘”并挂接到虚拟机上
Persistent Volume(简称PV)和与之相关联的Persistent Volume Claim (简称PVC)也起到了类似的作用。PV可以理解成 Kubernetes集群中的某个网络存储中对应的一块存储,它与Volume很类似,但有以下区别。
| Persistent Volume与Volume的区别 |
|---|
| PV只能是网络存储,不属于任何Node,但可以在每个Node上访问。 |
| PV并不是定义在Pod上的,而是独立于Pod之外定义。 |
| PV目前支持的类型包括: gcePersistentDisk、 AWSElasticBlockStore, AzureFileAzureDisk, FC (Fibre Channel). Flocker, NFS, isCSI, RBD (Rados Block Device)CephFS. Cinder, GlusterFS. VsphereVolume. Quobyte Volumes, VMware Photon.PortworxVolumes, ScalelO Volumes和HostPath (仅供单机测试)。 |
1 | apiversion: v1 |
PV的accessModes属性, 目前有以下类型:
ReadWriteOnce:读写权限、并且只能被单个Node挂载。
ReadOnlyMany:只读权限、允许被多个Node挂载。
ReadWriteMany:读写权限、允许被多个Node挂载。
如果某个Pod想申请某种类型的PV,则首先需要定义一个PersistentVolumeClaim (PVC)对象:
1 | kind: Persistentvolumeclaim |
引用PVC
1 | volumes: |
PV是有状态的对象,它有以下几种状态。 |
|---|
Available:空闲状态。 |
Bound:已经绑定到某个Pvc上。 |
Released:对应的PVC已经删除,但资源还没有被集群收回。 |
Failed: PV自动回收失败。 |
1.4.12 Namespace (命名空间)
Namespace (命名空间)是Kubernetes系统中非常重要的概念, Namespace在很多情况下用于实现 **多租户的资源隔离**。Namespace通过将集群内部的资源对象“分配”到不同的Namespace 中,形成逻辑上分组的不同项目、小组或用户组,便于不同的分组在共享使用整个集群的资源的同时还能被分别管理。Kubernetes集群在启动后,会创建一个名为"default"的Namespace,通过kubectl可以查看到:
|不同的namespace之间互相隔离|
|–|–|
|查看所有命名空间|kubectl get ns|
|查看当前命名空间|kubectl config get-contexts|
|设置命名空间|kubectl config set-context 集群名 –namespace=命名空间|
kub-system 本身的各种 pod,是kubamd默认的空间。pod使用命名空间相互隔离
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible] |
命名空间基本命令
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible] |
命名空间切换
1 | ┌──[root@vms81.liruilongs.github.io]-[~/.kube] |
或者可以这样切换名称空间
1 | kubectl config set-context $(kubectl config current-context) --namespace=<namespace> |
创建pod时指定命名空间
1 | apiVersion: v1 |
当我们给每个租户创建一个Namespace来实现多租户的资源隔离时,还能结合Kubernetes"的资源配额管理,限定不同租户能占用的资源,例如CPU使用量、内存使用量等。
Annotation (注解)
Annotation与Label类似,也使用key/value键值对的形式进行定义。
不同的是Label具有严格的命名规则,它定义的是Kubernetes对象的元数据(Metadata),并且用于Label Selector.
Annotation则是用户任意定义的“附加”信息,以便于外部工具进行查找, Kubernetes的模块自身会通过Annotation的方式标记资源对象的一些特殊信息。
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-pod-create] |
| 通常来说,用Annotation来记录的信息如下 |
|---|
| build信息、 release信息、Docker镜像信息等,例如时间戳、release id号、PR号、镜像hash值、 docker registry地址等。 |
| 日志库、监控库、分析库等资源库的地址信息。 |
| 程序调试工具信息,例如工具名称、版本号等。 |
| 团队的联系信息,例如电话号码、负责人名称、网址等。 |
第2章Kubernetes实践指南
3.8 Pod健康检查和服务可用性检查
Kubernetes 对 Pod 的健康状态可以通过两类探针来检查:LivenessProbe 和ReadinessProbe, kubelet定期执行这两类探针来诊断容器的健康状况。
| 探针类型 | 描述 |
|---|---|
| LivenessProbe探针 | 用于判断容器是否存活(Running状态) ,如果LivenessProbe探针探测到容器不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含LivenesspProbe探针,那么kubelet认为该容器的LivenessProbe探针返回的值永远是Success。 |
| ReadinessProbe探针 | 用于判断容器服务是否可用(Ready状态) ,达到Ready状态的Pod才可以接收请求。对于被Service管理的Pod, Service与Pod Endpoint的关联关系也将基于Pod是否Ready进行设置。如果在运行过程中Ready状态变为False,则系统自动将其从Service的后端Endpoint列表中隔离出去,后续再把恢复到Ready状态的Pod加回后端Endpoint列表。这样就能保证客户端在访问Service时不会被转发到服务不可用的Pod实例上。 |
LivenessProbe和ReadinessProbe均可配置以下三种实现方式。
| 方式 | 描述 |
|---|---|
| ExecAction | 在容器内部执行一个命令,如果该命令的返回码为0,则表明容器健康。 |
| TCPSocketAction | 通过容器的IP地址和端口号执行TC检查,如果能够建立TCP连接,则表明容器健康。 |
| HTTPGetAction | 通过容器的IP地址、端口号及路径调用HTTP Get方法,如果响应的状态码大于等于200且小于400,则认为容器健康。 |
对于每种探测方式,都需要设置initialDelaySeconds和timeoutSeconds两个参数,它们的含义分别如下。
| 参数 | 描述 |
|---|---|
| initialDelaySeconds: | 启动容器后进行首次健康检查的等待时间,单位为s。 |
| timeoutSeconds: | 健康检查发送请求后等待响应的超时时间,单位为s。当超时发生时, kubelet会认为容器已经无法提供服务,将会重启该容器。 |
Kubernetes的ReadinessProbe机制可能无法满足某些复杂应用对容器内服务可用状态的判断
所以Kubernetes从1.11版本开始,引入PodReady++特性对Readiness探测机制进行扩展,在1.14版本时达到GA稳定版,称其为Pod Readiness Gates。
通过Pod Readiness Gates机制,用户可以将自定义的ReadinessProbe探测方式设置在Pod上,辅助Kubernetes设置Pod何时达到服务可用状态(Ready) 。为了使自定义的ReadinessProbe生效,用户需要提供一个外部的控制器(Controller)来设置相应的Condition状态。
Pod的Readiness Gates在Pod定义中的ReadinessGate字段进行设置。下面的例子设置了一个类型为www.example.com/feature-1的新ReadinessGate:
| – |
|---|
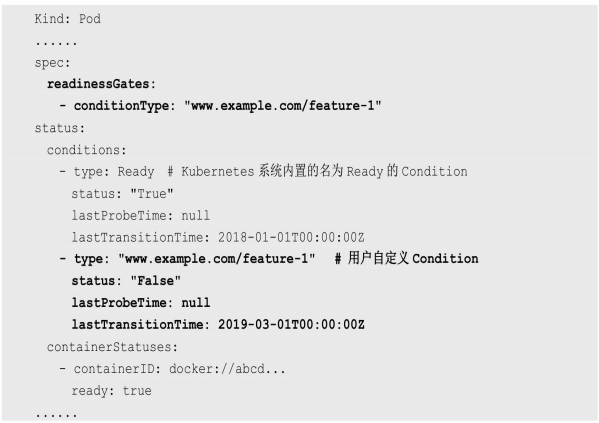 |
| 新增的自定义Condition的状态(status)将由用户自定义的外部控·制器设置,默认值为False. Kubernetes将在判断全部readinessGates条件都为True时,才设置Pod为服务可用状态(Ready为True) 。 |
3.9 pod 调度
3.9.8 Job:批处理调度
Kubernetes从1.2版本开始支持批处理类型的应用,我们可以通过Kubernetes Job资源对象来定义并启动一个批处理任务。
批处理任务通常并行(或者串行)启动多个计算进程去处理一批工作项(work item)处理完成后,整个批处理任务结束。
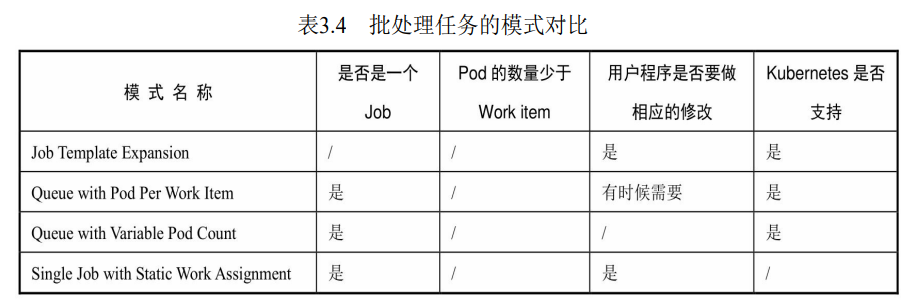
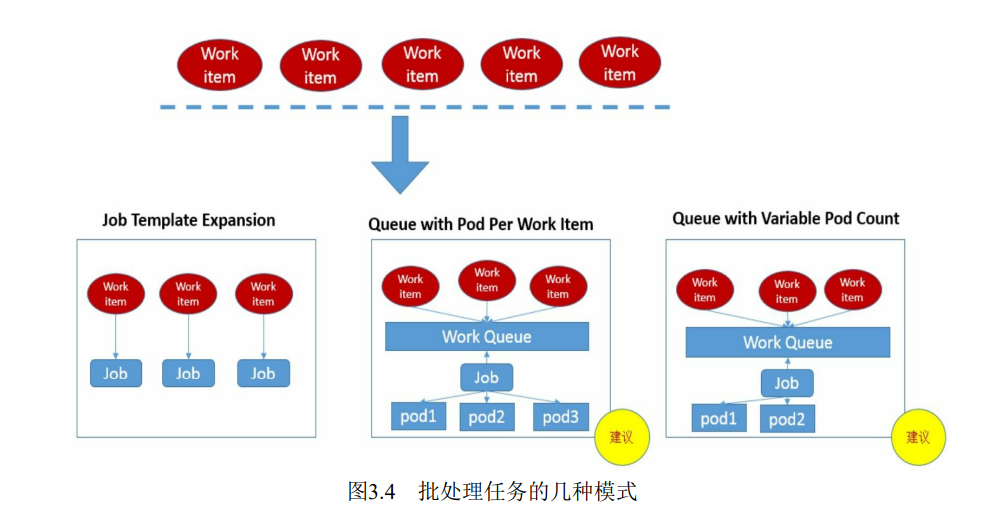
按照批处理任务实现方式的不同,批处理任务可以分为的几种模式。
| – | – |
|---|---|
| Job Template Expansion模式 | 一个Job对象对应一个待处理的Work item,有几个Work item就产生几个独立的Job,通常适合Workitem数量少、每个Work item要处理的数据量比较大的场景,比如有一个100GB的文件作为一个Work item,总共有10个文件需要处理。 |
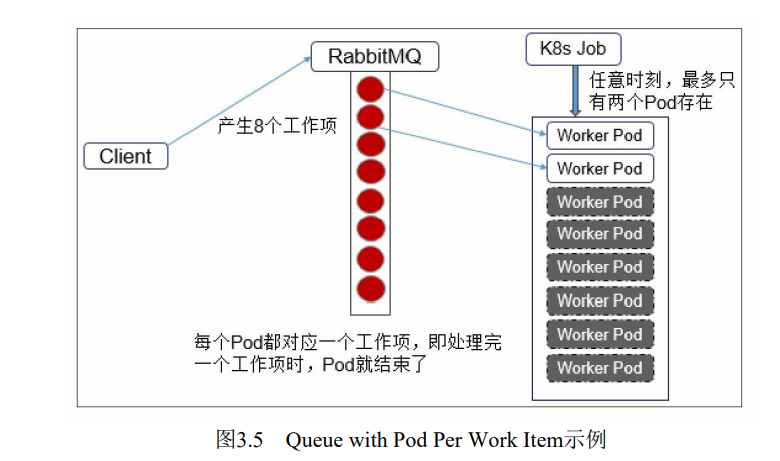
| Queue with Pod Per Work Item模式 | 采用一个任务队列存放Work item,一个Job对象作为消费者去完成这些Work item,在这种模式下, Job会启动N个Pod,每个Pod都对应一个Work item。 |
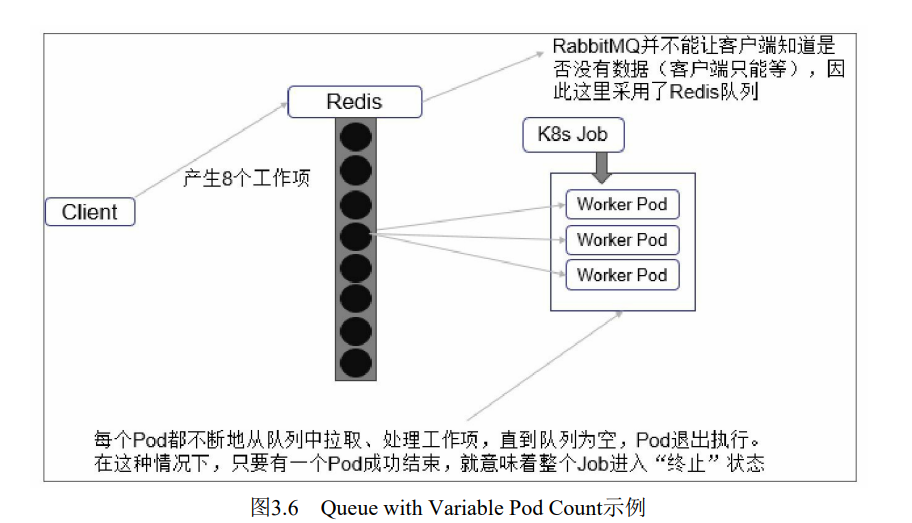
| Queue with Variable Pod Count模式 | 也是采用一个任务队列存放Work item,一个Job对象作为消费者去完成这些Work item,但与上面的模式不同, **Job启动的Pod数量是可变的**。 |
| Single Job with Static Work Assignment的模式 | 一个Job产生多个Pod,采用程序静态方式分配任务项 |
| – |
|---|
 |
 |
 |
 |
考虑到批处理的并行问题, Kubernetes将Job分以下三种类型。
| 类型 | 描述 |
|---|---|
| Non-parallel Jobs | 通常一个Job只启动一个Pod,除非Pod异常,才会重启该Pod,一旦此Pod正常结束, Job将结束。 |
| Parallel Jobs with a fixed completion count | 并行Job会启动多个Pod,此时需要设定Job的.spec.completions参数为一个正数,当正常结束的Pod数量达至此参数设定的值后, Job结束。此外, Job的.spec.parallelism参数用来控制并行度,即同时启动几个Job来处理Work Item. |
| Parallel Jobs with a work queue | 任务队列方式的并行Job需要一个独立的Queue, Work item都在一个Queue中存放,不能设置Job的.spec.completions参数,此时Job有以下特性。每个Pod都能独立判断和决定是否还有任务项需要处理。 如果某个Pod正常结束,则Job不会再启动新的Pod. 如果一个Pod成功结束,则此时应该不存在其他Pod还在工作的情况,它们应该都处于即将结束、退出的状态。 如果所有Pod都结束了,且至少有一个Pod成功结束,则整个Job成功结束。 |
3.9.9 Cronjob:定时任务
Kubernetes从1.5版本开始增加了一种新类型的Job,即类似LinuxCron的定时任务Cron Job,下面看看如何定义和使用这种类型的Job首先,确保Kubernetes的版本为1.8及以上。
运行下面的命令,可以更直观地了解Cron Job定期触发任务执行的历史和现状:
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-jobs-create] |
在Kubernetes 1.9版本后,kubectl命令增加了别名cj来表示cronjob,同时kubectl set image/env命令也可以作用在CronJob对象上了。
第4章 深入掌握Service
Service是Kubernetes的核心概念,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发到后端的各个容器应用上。具体涉及service的负载均衡机制、如何访问Service、 Headless Service, DNS服务的机制和实践、Ingress 7层路由机制等。
通过Service的定义, Kubernetes实现了一种分布式应用统一入口的定义和负载均衡机制。Service还可以进行其他类型的设置,例如设置多个端口号、直接设置为集群外部服务,或实现为Headless Service (无头服务)模式
4.1 Service定义详解
| 配置文件相关 |
|---|
 |
Service的类型type,指定Service的访间方式,默认值为ClusterlP.
| 方式 | 描述 |
|---|---|
| ClusterlP | 虚拟的服务IP地址,该地址用于Kubernetes集群内部的Pod访问,在Node上kube-proxy通过设置的iptables规则进行转发 |
| NodePort | 使用宿主机的端口,使能够访问各Node的外部客户端通过Node的IP地址和端口号就能访问服务。 |
| LoadBalancer | 使用外接负载均衡器完成到服务的负奉分发,需要在spec.status.loadBalancer字段指定外部负载均衡器的IP地址,并同时定义nodePort和clusterlp,用于公有云环境 |
4.2 Service的基本用法
一般来说,对外提供服务的应用程序需要通过某种机制来实现,对于容器应用最简便的方式就是通过TCP/IP机制及监听IP和端口号来实现。即PodIP+容器端口的方式
直接通过Pod的IP地址和端口号可以访问到容器应用内的服务,但是Pod的IP地址是不可靠的,如果容器应用本身是分布式的部署方式,通过多个实例共同提供服务,就需要在这些实例的前端设置一个负载均衡器来实现请求的分发。
Kubernetes中的Service就是用于解决这些问题的核心组件。通过kubectl expose命令来创建Service
新创建的Service,系统为它分配了一个虚拟的IP地址(ClusterlP) , Service所需的端口号则从Pod中的containerPort复制而来:
除了使用kubectl expose命令创建Service,我们也可以通过配置文件定义Service,再通过kubectl create命令进行创建
Service定义中的关键字段是ports和selector 。**ports定义部分指定了Service所需的虚拟端口号为8081,如果与Pod容器端口号8080不一样,所以需要再通过targetPort来指定后端Pod的端口号。selector定义部分设置的是后端Pod所拥有的label: **
4.2.0负载分发策略
基于 ClusterlP 提供的两种负载分发策略
目前 Kubernetes 提供了两种负载分发策略:RoundRobin和SessionAffinity
|负载分发策略
|–|
|RoundRobin|轮询模式,即轮询将请求转发到后端的各个Pod上。|
|SessionAffinity|基于客户端IP地址进行会话保持的模式,|
在默认情况下, Kubernetes采用RoundRobin模式对客户端请求进行,负载分发,但我们也可以通过设置service.spec.sessionAffinity=ClientIP来启用SessionAffinity策略。
4.2.1 多端口Service
一个容器应用也可能提供多个端口的服务,那么在Service的定义中也可以相应地设置为将多个端口对应到多个应用服务。
1 | - port: 8080 |
可以两个端口号使用了不同的4层协议—TCP和UDP:
1 | ports: |
4.2.2 外部服务Service
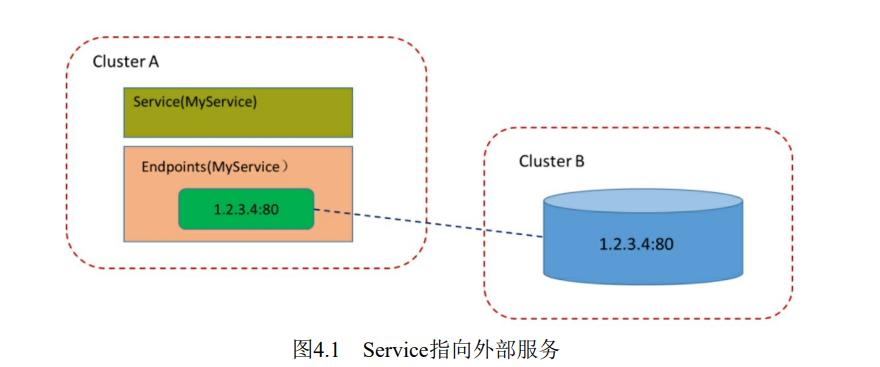
在某些环境中,应用系统需要将一个外部数据库作为后端服务进行连接,或将另一个集群或Namespace中的服务作为服务的后端,这时可.以通过创建一个无Label Selector的Service来实现:
1 | kind: Service |
通过该定义创建的是一个不带标签选择器的Service,即无法选择后端的Pod,系统不会自动创建Endpoint,因此需要手动创建一个和该Service同名的Endpoint,用于指向实际的后端访问地址。创建Endpoint的配置文件内容如下:
1 | kind: Endpoint |
| 外部服务Service |
|---|
 |
4.3 Headless Service
在某些应用场景中,开发人员希望自己控制负载均衡的策略,不使用Service提供的默认负载均衡的功能,或者应用程序希望知道属于同组服务的其他实例。Kubernetes提供了Headless Service来实现这种功能,即不为Service设置ClusterlP (入口IP地址) ,仅通过Label Selector将后端的Pod列表返回给调用的客户端。
1 | spec: |
Service就不再具有一个特定的ClusterIP地址,StatefulSet就是使用Headless Service为客户端返回多个服务地址的,对于“去中心化”类的应用集群,Headless Service将非常有用
4.4 从集群外部访问Pod或Service(服务的发布)
由于Pod和Service都是Kubernetes集群范围内的虚拟概念,所以集群外的客户端系统无法通过Pod的IP地址或者Service的虚拟IP地址和虚拟端口号访问它们。为了让外部客户端可以访问这些服务,可以将Pod或Service的端口号映射到宿主机,以使客户端应用能够通过物理机访问容器应用。
4.4.1 将容器应用的端口号映射到物理机
宿主机映射,当pod发生调度后,节点没法办运行
通过设置容器级别的hostPort,将容器应用的端口号映射到物理机上:
1 | ports: |
通过设置Pod级别的hostNetwork=true,该Pod中所有容器的端口号都将被直接映射到物理机上。 在设置hostNetwork=true时需要注意,在容器的ports定义部分如果不指定hostPort,则默认hostPort等于containerPort,如果指定了hostPort,则hostPort必须等于containerPort的值:
1 | spec |
4.4.2 将Service的端口号映射到物理机
通过设置nodePort映射到物理机,同时设置Service的类型为NodePort:
1 | apiversion: v1 |
**通过设置LoadBalancer映射到云服务商提供的LoadBalancer地址**。
4.5 DNS服务搭建和配置指南
**作为服务发现机制的基本功能,在集群内需要能够通过服务名对服务进行访问,这就需要一个集群范围内的DNS服务来完成从服务名到ClusterlP的解析**。
| 阶段 | DNS服务在Kubernetes的发展过程中经历了3个阶段 |
|---|---|
| 在Kubernetes 1.2版本时 | DNS服务是由SkyDNS提供的,它由4个容器组成: kube2sky、skydns, etcd和healthz, kube2sky容器监控Kubernetes中Service资源的变化,根据Service的名称和P地址信息生成DNS记录,并将其保存到etcd中; skydns容器从etcd中读取DNS记录,并为客户端容器应用提供DNS查询服务; healthz容器提供对skydns服务的建康检查功能。图4.3展现了SkyDNS的总体架构。 |
| 从Kubernetes 1.4版本开始 | SkyDNS组件便被KubeDNS替换,主要考虑是SkyDNS组件之间通信较多,整体性能不高。KubeDNS由3个容器组成: kubedns、 dnsmasq和sidecar,去掉了SkyDNS中的etcd存储,将DNS记录直接保存在内存中,以提高查询性能。kubedns容器监控Kubernetes中Service资源的变化,根据Service的名称和IP地址生成DNS记录,并将DNS记录保存在内存中; dnsmasq容器从kubedns中获取DNS记录,提供DNS缓存,为客户端容器应用提供DNS查询服务; sidecar提供对kubedns和dnsmasq服务的健康检查功能。 |
| 从Kubernetes 1.11版本开始 | Kubernetes集群的DNS服务由CoreDNS提供。CoreDNS是CNCF基金会的一个项目,是用Go语言实现的高性能、插件式、易扩展的DNS服务端。CoreDNS解决了KubeDNS的一些问题,例如dnsmasq的安全漏洞、externalName不能使用stubDomains设置,等等。CoreDNS支持自定义DNS记录及配置upstream DNS Server,可以统一管理Kubernetes基于服务的内部DNS和数据中心的物理DNS |
4.6 Ingress:HTTP 7层路由机制
Service的表现形式为IP:Port,即工作在TCP/IP层。
对于基于HTTP的服务来说,不同的URL地址经常对应到不同的后端服务或者虚拟服务器(Virtual Host)这些应用层的转发机制仅通过Kubernetes的Service机制是无法实现的。
从Kubernetes 1.1版本开始新增Ingress资源对象,用于将不同URL的访问请求转发到后端不同的Service,以实现HTTP层的业务路由机制。但是并不是说只能做7层路由,四层负载也可以
Kubernetes使用了一个Ingress策略定义和一个具体的Ingress Controller,两者结合并实现了一个完整的Ingress负载均衡器。
使用Ingress进行负载分发时是不是和kube-proxy没啥关系,直接分发到pod上了,使用Load Balancer和nodeport才会使用kube-proxy ?
使用Ingress进行负载分发时, Ingress Controller基于Ingress规则将客户端请求直接转发到Service对应的后端Endpoint (Pod)上,这样会跳过kube-proxy的转发功能, kube-proxy不再起作用。如果IngressController提供的是对外服务,则实际上实现的是边缘路由器的功能。 《Kubernetes权威指南》中的描述
控制器通过svc获取endpoints并获取对应的pod信息,然后通过nginx内部的lua代码进行处理
为使用Ingress,需要创建Ingress Controller(带一个默认backend服务)和Ingress策略设置来共同完成。下面通过一个例子分三步说明Ingress Controller和Ingress策略的配置方法,以及客户端如何访问Ingress提供的服务。
4.6.1 创建Ingress Controller和默认的backend服务
在定义Ingress策略之前,需要先部署Ingress Controller,以实现为所有后端Service都提供一个统一的入口。Ingress Controller需要实现基于不同HTTP URL向后转发的负载分发规则,并可以灵活设置7层负载分发策略。
如果公有云服务商能够提供该类型的HTTP路由LoadBalancer,则也可设置其为Ingress Controller。在Kubernetes中, Ingress Controller将以Pod的形式运行,监控APIServer的/ingress接口后端的backend services,如果Service发生变化,则Ingress Controller应自动更新其转发规则。
第3章Kubernetes核心原理
3.1 Kubernetes API Server原理分析
官网很详细,小伙伴系统学习可以到官网:https://kubernetes.io/zh/docs/tasks/administer-cluster/access-cluster-api/
Kubernetes API Server的核心功能是提供了Kubernetes各类资源对象(如Pod,RC, Service等)的增、删、改、查及Watch等HTTP Rest接口,成为集群内各个功能模块之间数据交互和通信的中心枢纽,是整个系统的数据总线和数据中心。除此之外,它还有以下一些功能特性。
(1)是集群管理的API入口。
(2)是资源配额控制的入口。
(3)提供了完备的集群安全机制。
3.1.1 Kubernetes API Server 概述
Kubernetes API Server通过一个名为kube-apiserver的进程提供服务,该进程运行在Master节点上,如果小伙伴使用二进制方式安装k8s,会发现,kube-apiserver是docker之后第一个要启动的服务
旧版本中kube-apiserver进程在本机的8080端口(对应参数-insecure-port)提供REST服务。
新版本中启动HTTPS安全端口(--secure-port=6443)来启动安全机制,加强REST API访问的安全性。这里需要说明的是,好像是从1.20开始就不支持了,在apiserver配置文件里添加 –insecure-port=8080会导致启动不了,所以不在支持直接http的方式访问(可以用代理)
在高版本的环境中,有时候环境起不来,会报错说6443端口没有开放
通常我们可以通过命令行工具kubectl来与Kubernetes API Server交互,它们之间的接口是REST调用。
使用 kubectl 代理
如果我们只想对外暴露部分REST服务,则可以在Master或其他任何节点上通过运行kubect proxy进程启动一个内部代理来实现。
1 | ┌──[root@vms81.liruilongs.github.io]-[~] |
当然,我们也可以拒绝访问某一资源,比如pod
1 | ┌──[root@vms81.liruilongs.github.io]-[~] |
1 | ┌──[root@vms81.liruilongs.github.io]-[~] |
kubectl proxy具有很多特性,最实用的一个特性是提供简单有效的安全机制,比如采用白名单来限制非法客户端访问时,只要增加下面这个参数即可:
1 | --accept-hosts="^localhost$, ^127\\.0\\.0\\.1$,^\\[::1\\]$" |
不使用 kubectl 代理
通过将身份认证令牌直接传给 API 服务器,可以避免使用 kubectl 代理,像这样:
使用 grep/cut 方式:
1 | # 查看所有的集群,因为你的 .kubeconfig 文件中可能包含多个上下文 |
编程方式访问 API
python
要使用 Python 客户端,运行下列命令: pip install kubernete
1 | PS E:\docker> pip install kubernetes |
将 ~/.kube 的config文件的内容复制到本地目录,保存为文件kubeconfig.yaml
1 | ┌──[root@vms81.liruilongs.github.io]-[~] |
| python |
|---|
 |
1 | #!/usr/bin/env python |
输出所有的pod和对应的node IP
1 | PS D:\code\blogger\blogger\资源> python .\k8s_api.py |
Java
1 | # 克隆 Java 库 |
| java的客户端 |
|---|
 |
1 | package io.kubernetes.client.examples; |
输出所有pod
1 | D:\Java\jdk1.8.0_251\bin\java.exe 。。。 |
node
1 | const k8s = require('@kubernetes/client-node'); |
3.1.2 独特的Kubernetes Proxy API接口
Kubernetes Proxy API接口,作用是代理REST请求,即Kubernetes API Server把收到的REST请求转发到某个Node上的kubelet·守护进程的REST端口上,由该kubelet进程负责响应。
1 | ┌──[root@vms81.liruilongs.github.io]-[~] |
1 | ┌──[root@vms81.liruilongs.github.io]-[~] |
需要说明的是:这里获取的Pod的信息数据来自Node而非etcd数据库,所以两者可能在·某些时间点会有偏差。此外,如果kubelet进程在启动时包含-enable-debugging-handlers=true参数,那么Kubernetes Proxy API还会增加其他的接口信息
3.1.3 集群功能模块之间的通信
Kubernetes API Server 作为集群的核心,负责集群各功能模块之间的通信。集群内的各个功能模块通过API Server将信息存入etcd,当需要获取和操作这些数据时,则通过API Server提供的REST接口(用GET, LIST或WATCH方法)来实现,从而实现各模块之间的信息交互。
交互场景:
kubelet进程与API Server的交互 每个Node节点上的kubelet每隔一个时间周期,就会调用一次API Server的REST接口报告自身状态, API Server接收到这些信息后,将节点状态信息更新到etcd中。 , kubelet也通过API Server的Watch接口监听Pod信息,如果监听到新的Pod副本被调度绑定到本节点,则执行Pod对应的容器的创建和启动逻辑;如果监听到Pod对象被删除,则删除本节点上的相应的Pod容器;如果监听到修改Pod信息,则kubelet监听到变化后,会相应地修改本节点的Pod容器。
kube-controller-manager进程与API Server的交互。 kube-controller-manager中的Node Controller模块通过API Sever提供的Watch接口,实时监控Node的信息,并做相应处理
kube-scheduler与API Server的交互。当Scheduler通过API Server的Watch接口监听到新建Pod副本的信息后,它会检索所有符合该Pod要求的Node列表,开始执行Pod调度逻辑,调度成功后将Pod绑定到目标节点上。
为了缓解集群各模块对API Server的访问压力,各功能模块都采用缓存机制来缓存数据。各功能模块定时从API Server获取指定的资源对象信息(通过LIST及WATCH方法),然后将这些信息保存到本地缓存,功能模块在某些情况下不直接访问API Server,而是通过访问缓存数据来间接访问API Server.
3.2 Controller Manager 原理分析
Controller Manager作为集群内部的管理控制中心,负责集群内的Node,Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)等的管理,当某个Node意外宕机时, Controller Manager会及时发现此故障并执行自动化修复流程,确保集群始终处于预期的工作状态。
Controller Manager内部包含Replication Controller, Node Controller, ResourceQuota Controller, Namespace Controller, ServiceAccount Controller, Token Controller,Service Controller及Endpoint Controller等多个Controller,每种Controller都负责一种具体的控制流程,而Controller Manager正是这些Controller的核心管理者。
3.2.1 Replication Controller
在新版的K8s中,RC用的相对来说少了,更多是用deploy来创建多个pod副本,这里我们也简单学习下.
Replication Controller的核心作用是确保在任何时候集群中一个RC所关联的Pod副本数量保持预设值。
需要注意的一点是: 只有当Pod的重启策略是Always时(RestartPolicy=Always), Replication Controller才会管理该Pod的操作(例如创建、销毁、重启等)
RC 中的pod模板一旦创建完成,就和RC中的模板没有任何关系。,Pod可以通过修改标签来实现脱离RC的管控。可以用于 **将Pod从集群中迁移、数据修复等调试**。
对于被迁移的Pod副本, RC会自动创建一个新的,副本替换被迁移的副本。需要注意的是,删除一个RC不会影响它所创建的Pod,如果想删除一个RC所控制的Pod,则需要将该RC的副本数(Replicas)属性设置为0,这样所有的Pod副本都会被自动删除。
Replication Controller的职责:
Replication Controller的职责 |
|---|
| 确保当前集群中有且仅有N个Pod实例, N是RC中定义的Pod副本数量。 |
| 通过调整RC的spec.replicas属性值来实现系统扩容或者缩容。 |
| 通过改变RC中的Pod模板(主要是镜像版本)来实现系统的滚动升级。 |
使用场景
| 使用场景 |
|---|
| 重新调度(Rescheduling):副本控制器都能确保指定数量的副本存在于集群中 |
| 弹性伸缩(Scaling),手动或者通过自动扩容代理修改副本控制器的spec.replicas属性值,非常容易实现扩大或缩小副本的数量。 |
| 滚动更新(Rolling Updates),副本控制器被设计成通过逐个替换Pod的方式来辅助服务的滚动更新。即现在的deployment资源的作用,通过新旧两个RC 实现滚动更新 |
3.2.2 Node Controller
kubelet进程在启动时通过API Server注册自身的节点信息,并定时向API Server汇报状态信息, API Server接收到这些信息后,将这些信息更新到etcd中, etcd中存储的节点信息包括节点健康状况、节点资源、节点名称、节点地址信息、操作系统版本、Docker版本、kubelet版本等。
节点健康状况包含“就绪” (True) “未就绪” (False)和“未知" (Unknown)三种。
Node Controller通过API Server实时获取Node的相关信息,实现管理和监控集群中的各个Node节点的相关控制功能, Node Controller的核心工作流程如图。
| Node Controller的核心工作流程如图 |
|---|
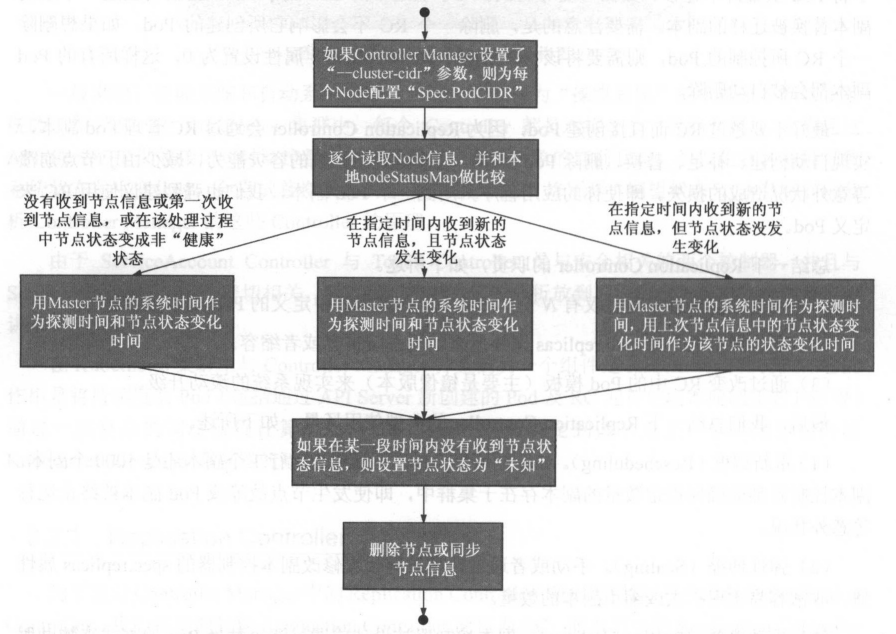 |
Controller Manager在启动时如果设置了-cluster-cidr参数,那么为每个没有设置Spec.PodCIDR的Node节点生成一个CIDR地址,并用该CIDR地址设置节点的Spec.PodCIDR属性,这样做的目的是防止不同节点的CIDR地址发生冲突。
逐个读取节点信息,多次尝试修改nodestatusMap中的节点状态信息,将该节点信息和Node Controller的nodeStatusMap中保存的节点信息做比较。
| 节点状态 |
|---|
如果判断出没有收到kubelet发送的节点信息、第1次收到节点kubelet发送的节点信息,或在该处理过程中节点状态变成非“健康”状态 |
则在nodeStatusMap中保存该节点的状态信息,并用Node Controller所在节点的系统时间作为探测时间和节点状态变化时间。 |
如果判断出在指定时间内收到新的节点信息,且节点状态发生变化 |
则在nodeStatusMap中保存该节点的状态信息,并用NodeController所在节点的系统时间作为探测时间和节点状态变化时间。 |
如果判断出在指定时间内收到新的节点信息,但节点状态没发生变化 |
则在nodeStatusMap中保存该节点的状态信息,并用Node Controller所在节点的系统时间作为探测时间,用上次节点信息中的节点状态变化时间作为该节点的状态变化时间。 |
如果判断出在某一段时间(gracePeriod)内没有收到节点状态信息 |
则设置节点状态为“未知” (Unknown),并且通过API Server保存节点状态。 |
如果节点状态变为非“就绪”状态,则将节点加入待删除队列,,否则将节点从该队列中删除。
如果节点状态为非“就绪”状态,且系统指定了Cloud Provider,则Node Controller 调用Cloud Provider查看节点,若发现节点故障,则删除etcd中的节点信息,并删除和该节点相关的Pod等资源的信息。
3.2.3 ResourceQuota Controller
Kubernetes提供了资源配额管理( ResourceQuotaController),确保了指定的资源对象在任何时候都不会超量占用系统物理资源,导致整个系统运行紊乱甚至意外宕机,对整个集群的平稳运行和稳定性有非常重要的作用。
Kubernetes支持资源配额管理。
容器级别,可以对CPU和Memory进行限制。
Pod级别,可以对一个Pod内所有容器的可用资源进行限制。
Namespace级别,为Namespace (多租户)级别的资源限制,Pod数量;Replication Controller数量; Service数量;ResourceQuota数量;Secret 数量;可持有的PV (Persistent Volume)数量。
Kubernetes的配额管理是通过Admission Control (准入控制)来控制的, Admission Control当前提供了两种方式的配额约束,分别是LimitRanger与ResourceQuota。其中
LimitRanger作用于Pod和Container上,ResourceQuota则作用于Namespace上,限定一个Namespace里的各类资源的使用总额。
如果在
Pod定义中同时声明了LimitRanger,则用户通过API Server请求创建或修改资源时,Admission Control会计算当前配额的使用情况,如果不符合配额约束,则创建对象失败。
对于定义了
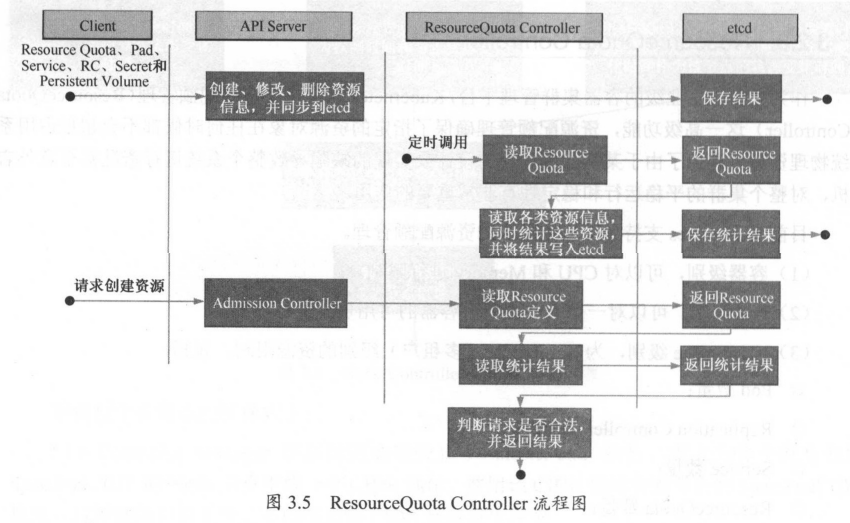
ResourceQuota的Namespace,ResourceQuota Controller组件则负责定期统计和生成该Namespace下的各类对象的资源使用总量,统计结果包括Pod, Service,RC、Secret和Persistent Volume等对象实例个数,以及该Namespace下所有Container实例所使用的资源量(目前包括CPU和内存),然后将这些统计结果写入etcd的resourceQuotaStatusStorage目录(resourceQuotas/status)中。
| ResourceQuota Controller 流程圖 |
|---|
 |
3.2.4 Namespace Controller
通过API Server可以创建新的Namespace并保存在etcd中, Namespace Controller定时通过API Server读取这些Namespace信息。
| 删除步骤 |
|---|
如果Namespace被API标识为优雅删除(通过设置删除期限,即DeletionTimestamp属性被设置),则将该NameSpace的状态设置成”Terminating“并保存到etcd中。同时Namespace Controller删除该Namespace下的ServiceAccount, RC, Pod.Secret, PersistentVolume, ListRange, ResourceQuota和Event等 **资源对象**。 |
当Namespace的状态被设置成”Terminating“后,由Admission Controller的NamespaceLifecycle插件来 阻止 为该Namespace创建新的资源。 |
在Namespace Controller删除完该Namespace中的所有资源对象后, Namespace Controller对该Namespace执行finalize操作,删除Namespace的spec.finalizers域中的信息 |
如果Namespace Controller观察到Namespace设置了删除期限,同时Namespace的spec.finalizers域值是空的,那么Namespace Controller将通过API Server删除该Namespace资源。 |
3.2.5 Service Controller与Endpoint Controller
Service, Endpoints与Pod的关系
Endpoints表示一个Service对应的所有Pod副本的访问地址,而EndpointsController就是负责生成和维护所有Endpoints对象的控制器。
| – |
|---|
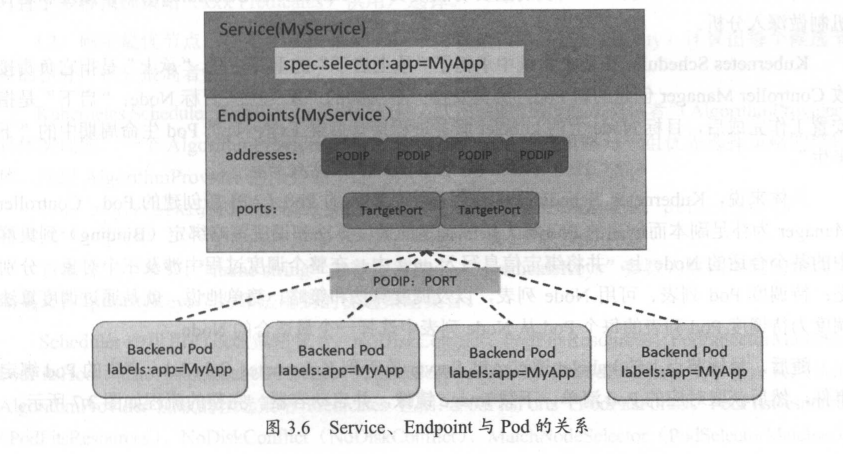 |
Endpoint Controller负责监听Service和对应的Pod副本的变化,如果监测到Service被删除,则删除和该Service同名的Endpoints对象。如果监测到新的Service被创建或者修改,则根据该Service信息获得相关的Pod列表,然后创建或者更新Service对应的Endpoints对象。如果监测到Pod的事件,则更新它所对应的Service的Endpoints对象(增加、删除或者修改对应的Endpoint条目)
Endpoints对象是在哪里被使用的呢?
每个
Node上的kube-proxy进程,kube-proxy进程获取每个Service的Endpoints,实现了Service的负载均衡功能。
Service Controller的作用,它其实是属于Kubernetes集群与外部的云平台之间的一个接口控制器。
Service Controller监听Service的变化,如果是一个LoadBalancer类型的Service (externalLoadBalancers-true),则Service Controller确保外部的云平台上该Service对应的LoadBalancer实例被相应地创建、删除及更新路由转发表(根据Endpoints的条目)。
5.4 kubelet运行机制解析
在Kubernetes集群中,在每个Node (又称Minion)上都会启动一个kubelet服务进程。该进程用于处理Master下发到本节点的任务(调度器调度这个节点的pod),管理Pod及Pod中的容器。
每个kubelet进程都会在API Server上注册节点自身的信息,定期向Master汇报节点资源的使用情况,并通过cAdvisor监控容器和节点资源。
嗯,可以这样理解,k8s中,master节点相当于总经理在总部,node节点相当于省市区域,kubelet相当于区域经理,负责处理总经理的指示和要求,同时管理省市公司的多个员工pod,这里总公司有一个OA系统,叫APIService,kubelet会在OA发布信息,定期的通过oA向master汇报区域员工的工作,同时通过cAdvisor对员工起一个监督作用
5.4.1 节点管理
节点通过设置kubelet的启动参数“--register-node”,来决定是否向API Server注册自己。如果该参数的值为true,那么kubelet将试着通过API Server注册自己。在自注册时,kubelet启动时还包含下列参数。
--api-servers:API Server的位置。--kubeconfig:kubeconfig文件,用于访问API Server的安全配置文件。--cloud-provider:云服务商(IaaS)地址,仅用于公有云环境。
当前每个kubelet都被授予创建和修改任何节点的权限。但是在实践中,它仅仅创建和修改自己。将来,我们计划限制kubelet的权限,仅允许它修改和创建所在节点的权限。如果在集群运行过程中遇到集群资源不足的情况,用户就很容易通过添加机器及运用kubelet的自注册模式来实现扩容。
在某些情况下,Kubernetes集群中的某些kubelet没有选择自注册模式,用户需要自己去配置Node的资源信息,同时告知Node上Kubelet API Server的位置。
集群管理者能够创建和修改节点信息。如果管理者希望手动创建节点信息,则通过设置kubelet的启动参数“--register-node=false”即可完成。
kubelet在启动时通过API Server注册节点信息,并定时向API Server发送节点的新消息,API Server在接收到这些信息后,将这些信息写入etcd。通过kubelet的启动参数“-node-status-update-frequency”设置kubelet每隔多长时间向API Server报告节点状态,默认为10s。
5.4.2 Pod管理
kubelet通过以下几种方式获取自身Node上要运行的Pod清单。
文件:kubelet启动参数--config指定的配置文件目录下的文件(默认目录为“/etc/kubernetes/manifests/”)。通过--file-check-frequency设置检查该文件目录的时间间隔,默认为20s。HTTP端点(URL):通过“-manifest-url”参数设置。通过--http-check-frequency设置检查该HTTP端点数据的时间间隔,默认为20s。API Server:kubelet通过API Server监听etcd目录,同步Pod列表。
所有以非API Server方式创建的Pod都叫作Static Pod。kubelet将Static Pod的状态汇报给API Server,API Server为该Static Pod创建一个Mirror Pod和其相匹配。Mirror Pod的状态将真实反映Static Pod的状态。
当Static Pod被删除时,与之相对应的Mirror Pod也会被删除。
在本章中只讨论通过API Server获得Pod清单的方式。kubelet通过API Server Client使用Watch加List的方式监听“/registry/nodes/$”当前节点的名称和“registry/pods”目录,将获取的信息同步到本地缓存中。
kubelet监听etcd,所有针对Pod的操作都会被kubelet监听。如果发现有新的绑定到本节点的Pod,则按照Pod清单的要求创建该Pod。
如果发现本地的Pod被修改,则kubelet会做出相应的修改,比如在删除Pod中的某个容器时,会通过Docker Client删除该容器。
如果发现删除本节点的Pod,则删除相应的Pod,并通过Docker Client删除Pod中的容器。
kubelet读取监听到的信息,如果是创建和修改Pod任务,则做如下处理。
- 为该Pod创建一个数据目录。
- 从API Server读取该Pod清单。
- 为该Pod挂载外部卷(External Volume)。
- 下载Pod用到的
Secret。 - 检查已经运行在节点上的Pod,如果该Pod没有
容器或Pause容器(“kubernetes/pause”镜像创建的容器)没有启动,则先停止Pod里所有容器的进程。如果在Pod中有需要删除的容器,则删除这些容器。 - 用
“kubernetes/pause”镜像为每个Pod都创建一个容器。该Pause容器用于接管Pod中所有其他容器的网络。每创建一个新的Pod,kubelet都会先创建一个Pause容器,然后创建其他容器。“kubernetes/pause”镜像大概有200KB,是个非常小的容器镜像。 - 为Pod中的每个容器做如下处理。
- 为容器计算一个Hash值,然后用容器的名称去查询对应Docker容器的Hash值。若查找到容器,且二者的Hash值不同,则停止Docker中容器的进程,并停止与之关联的Pause容器的进程;若二者相同,则不做任何处理。
- 如果容器被终止了,且容器没有指定的restartPolicy(重启策略),则不做任何处理。
- 调用Docker Client下载容器镜像,调用Docker Client运行容
器。
5.4.3 容器健康检查
Pod通过两类探针来检查容器的健康状态。
LivenessProbe探针
一类是LivenessProbe探针,用于判断容器是否健康并反馈给kubelet。如果LivenessProbe探针探测到容器不健康,则kubelet将删除该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含LivenessProbe探针,那么kubelet认为该容器的LivenessProbe探针返回的值永远是Success;
ReadinessProbe探针
另一类是ReadinessProbe探针,用于判断容器是否启动完成,且准备接收请求。如果ReadinessProbe探针检测到容器启动失败,则Pod的状态将被修改,Endpoint Controller将从Service的Endpoint中删除包含该容器所在Pod的IP地址的Endpoint条目。
kubelet定期调用容器中的LivenessProbe探针来诊断容器的健康状况。LivenessProbe包含以下3种实现方式。
- ExecAction:在容器内部执行一个命令,如果该命令的退出状态码为0,则表明容器健康。
- TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果端口能被访问,则表明容器健康。
- HTTPGetAction:通过容器的IP地址和端口号及路径调用HTTP Get方法,如果响应的状态码大于等于200且小于等于400,则认为容器状态健康。
关于更多小伙伴们可以看看我之前的博文关于 Kubernetes中Pod健康检测和服务可用性检查的一些笔记
资源监控
在新的Kubernetes监控体系中,MetricsServer用于提供Core Metrics(核心指标),包括Node和Pod的CPU和内存使用数据。其他Custom Metrics(自定义指标)则由第三方组件(如Prometheus)采集和存储。
第6章 深入分析集群安全机制
Kubernetes通过一系列机制来实现集群的安全控制,其中包括API Server的认证授权、准入控制机制及保护敏感信息的Secret机制等。集群的安全性必须考虑如下几个目标。
| 安全目标 |
|---|
| 保证容器与其所在宿主机的隔离。 |
| 限制容器给基础设施或其他容器带来的干扰。 |
| 最小权限原则一合理限制所有组件的权限,确保组件只执行它被授权的行为,通过限制单个组件的能力来限制它的权限范围。 |
| 明确组件间边界的划分。 |
| 划分普通用户和管理员的角色。 |
| 在必要时允许将管理员权限赋给普通用户。 |
| 允许拥有Secret数据(Keys, Certs, Passwords)的应用在集群中运行。 |
下面分别从Authentication,Authorization, AdmissionControl,Secret和Service Account等方面来说明集群的安全机制。
6.1 API Server认证管理
我们知道, Kubernetes集群中所有资源的访问和变更都是通过Kubernetes API Server的REST API来实现的,所以集群安全的关键点就在于如何鉴权和授权
Kubernetes集群提供了3种级别的客户端身份认证方式
- 最严格的HTTPS证书认证:基于CA根证书签名的双向数字证书认证方式
- HTTP Token认证:通过一个Token来识别合法用户。
- HTTP Base认证:通过用户名+密码的方式认证,这个只有1.19之前的版本适用,之后的版本不在支持
HTTPS证书认证的原理。
CA认证涉及诸多概念,比如根证书、自签名证书、密钥、私钥、·加密算法及HTTPS等,
(1) HTTPS通信双方的服务器端向CA机构申请证书, CA机构是可信的第三方机构,它可以是一个公认的权威企业,也可以是企业自身。企业内部系统一般都用企业自身的认证系统。CA机构下发根证书、服务端证书及私钥给申请者。
(2) HTTPS通信双方的客户端向CA机构申请证书, CA机构下发根证书、客户端证书及私钥给申请者。
(3)客户端向服务器端发起请求,服务端下发服务端证书给客户端。客户端接收到证书后,通过私钥解密证书,并利用服务器端证书中的公钥认证证书信息比较证书里的消息,例如,比较域名和公钥与服务器刚刚发送的相关消息是否一致,如果一致,则客户端认可这个服务器的合法身份。
(4)客户端发送客户端证书给服务器端,服务端在接收到证书后,通过私钥解密证书,获得客户端证书公钥,并用该公钥认证证书信息,确认客户端是否合法。
(5)客户端通过随机密钥加密信息,并发送加密后的信息给服务端。在服务器端和客户端协商好加密方案后,客户端会产生一个随机的密钥,客户端通过协商好的加密方案加密该随机密钥,并发送该随机密钥到服务器端。服务器端接收这个密钥后,双方通信的所有内容都通过该随机密钥加密。
上述是双向认证SSL协议的具体通信过程,这种情况要求服务器和用户双方都有证书。单向认证SSL协议则不需要客户端拥有CA证书,对于上面的步骤,只需将服务器端验证客户证书的过程去掉,之后协商对
HTTP Token的认证是用一个很长的特殊编码方式的并且难以被模仿的字符串-Token来表明客户身份的一种方式。在通常情况下, Token是一个很复杂的字符串,比如我们用私钥签名一个字符串后的数据就可以被当作一个Token。此外,每个Token对应一个用户名,存储在APIServer能访问的一个文件中。当客户端发起API调用请求时,需要在HTTP Header里放入Token,这样一来, API Server就能识别合法用户和非法用户了。
6.2 API Server授权管理
当客户端发起API Server调用时, API Server内部要先进行用户认证,然后执行用户鉴权流程,即通过鉴权策略来决定一个API调用是否合法。想来对于开发的小伙伴并不陌生,常用的Spring Security等安全框架,都会涉及认证和鉴权的过程。
既然鉴权,那必有授权的过程,简单地说,授权就是授予不同的用户不同的访问权限。
API Server目前支持以下几种授权策略(通过API Server的启动参数”--authorization-mode“设置)。
| 策略 | 描述 |
|---|---|
| AlwaysDeny | 表示拒绝所有请求,一般用于测试。 |
| AlwaysAllow | 允许接收所有请求,如果集群不需要授权流程,则可以采用该策略,这也是Kubernetes的默认配置。 |
| ABAC (Attribute-Based Access Control) | 基于属性的访问控制,表示使用用户配置的授权规则对用户请求进行匹配和控制。 |
| Webhook | 通过调用外部REST服务对用户进行授权。 |
| RBAC | Role-Based Access Control,基于角色的访问控制。 |
| Node | 是一种专用模式,用于对kubelet发出的请求进行访问控制。 |
6.2.3 RBAC授权模式详解
RBAC(Role-Based Access Control,基于角色的访问控制)在Kubernetes的1.5版本中引入,在1.6版本时升级为Beta版本,在1.8版本时升级为GA。作为kubeadm安装方式的默认选项,足见其重要程度。相对于其他访问控制方式,新的RBAC具有如下优势。
- 对集群中的资源和非资源权限均有完整的覆盖。
- 整个RBAC完全由几个API对象完成,同其他API对象一样,可以用kubectl或API进行操作。
- 可以在运行时进行调整,无须重新启动API Server。
要使用RBAC授权模式,需要在API Server的启动参数中加上–authorization-mode=RBAC
1.RBAC的API资源对象说明RBAC引入了4个新的顶级资源对象:
Role,ClusterRole,RoleBinding和ClusterRoleBinding
同其他API资源对象一样,用户可以使用kubectl或者API调用等方式操作这些资源对象。
资源文件属性
- apiGroups:支持的API组列表,例如“apiVersion:batch/v1”,“apiVersion: extensions:v1beta1”,“apiVersion: apps/v1beta1”等
- resources:支持的资源对象列表,例如pods、deployments、jobs等。
- verbs:对资源对象的操作方法列表,例如get、watch、list、delete、replace、patch等
RBAC的API资源对象说明
- 角色(Role)
一个角色就是一组权限的集合,这里的权限都是许可形式的,不存在拒绝的规则。在一个命名空间中,可以用角色来定义一个角色,如果是集群级别的,就需要使用ClusterRole了。角色只能对命名空间内的资源进行授权 - 集群角色(ClusterRole)集群角色除了具有和角色一致的命名空间内资源的管理能力,因其集群级别的范围,还可以用于以下特殊元素的授权。
- 集群范围的资源,例如Node.
- 非资源型的路径,例如“/api”
- 包含全部命名空间的资源,例如pods (用于kubectl get pods -all-namespaces这样的操作授权)。
- 角色绑定(RoleBinding)和集群角色绑定ClusterRoleBinding)角色绑定或集群角色绑定用来把一个角色绑定到一个目标上,绑定目标可以是User (用户) 、Group (组)或者Service Account。
- 使用RoleBinding为某个命名空间授权,
- 使用ClusterRoleBinding为集群范围内授权。
RoleBinding可以引用Role进行授权。RoleBinding也可以引用ClusterRole,对属于同一命名空间内ClusterRole定义的资源主体进行授权
集群角色绑定中的角色只能是集群角色,用于进行集群级别或者对所有命名空间都生效的授权
6.4 Service Account
Service Account也是一种账号,但它并不是给Kubernetes集群的用户
(系统管理员、运维人员、租户用户等)用的,而是给运行在Pod里的
进程用的,它为Pod里的进程提供了必要的身份证明。
第七章 网络原理
7.1 Kubernetes网络模型
Kubernetes网络模型设计的一个基础原则是:
每个Pod都拥有一个独立的IP地址,并假定所有Pod都在一个可以直接连通的、扁平的网络空间中。
所以不管它们是否运行在同一个Node (宿主机)中,都要求它们可以直接通过对方的IP进行访问。
设计这个原则的原因是,用户不需要额外考虑如何建立Pod之间的连接,也不需要考虑如何将容器端口映射到主机端口等问题。
在Kubernetes的世界里, IP是以Pod为单位进行分配的。Pod内部的所有容器共享一个网络堆栈(相当于一个网络命名空间,它们的IP地址、网络设备、配置等都是共享的)
按照这个网络原则抽象出来的为每个Pod都设置一个IP地址的模型也被称作IP-per-Pod模型。
由于Kubernetes的网络模型假设Pod之间访问时使用的是对方Pod的实际地址,所以一个Pod内部的应用程序看到的自己的IP地址和端口与集群内其他Pod看到的一样。
它们都是Pod实际分配的IP地址。将IP地址和端口在Pod内部和外部都保持一致,也就不需要使用NAT来进行地址转换了。Kubernetes的网络之所以这么设计,主要原因就是可以兼容过去的应用。
当然,我们使用Linux命令”ip addr show”也能看到这些地址,和程序看到的没有什么区别。所以这种IP-per-Pod的方案很好地利用了现有的各种域名解析和发现机制。
为每个Pod都设置一个IP地址的模型还有另外一层含义,那就是同一个Pod内的不同容器会共享同一个网络命名空间,也就是同一个Linux网络协议栈。这就意味着同一个Pod内的容器可以通过localhost来连接对方的端口。这种关系和同一个VM内的进程之间的关系是一样的,看起来Pod内容器之间的隔离性减小了,而且Pod内不同容器之间的端口是共享的,就没有所谓的私有端口的概念了。
如果你的应用必须要使用一些特定的端口范围,那么你也可以为这些应用单独创建一些Pod。
对那些没有特殊需要的应用,由于Pod内的容器是共享部分资源的,所以可以通过共享资源互相通信,这显然更加容易和高效。针对这些应用,虽然损失了可接受范围内的部分隔离性,却也是值得的。
IP-per-Pod模式和Docker原生的通过动态端口映射方式实现的多节点访问模式有什么区别呢?
Docker的动态端口映射会引入端口管理的复杂性,而且访问者看到的IP地址和端口与服务提供者实际绑定的不同(因为NAT的缘故,它们都被映射成新的地址或端口了) ,这也会引起应用配置的复杂化。,标准的DNS等名字解析服务也不适用了,甚至服务注册和发现机制都将迎来挑战,因为在端口映射情况下,服务自身很难知道自己对外暴露的真实的服务IP和端口,外部应用也无法通过服务所在容器的私有IP地址和端口来访问服务。
P-per-Pod模型是一个简单的兼容性较好的模型。从该模型的网络的端口分配、域名解析、服务发现、负载均衡、应用配置和迁移等角度来看, Pod都能够被看作一台独立的虚拟机或物理机。按照这个网络抽象原则, Kubernetes对网络有什么前提和要求呢?Kubernetes对集群网络有如下要求。
(1)所有容器都可以在不用NAT的方式下同别的容器通信。
(2)所有节点都可以在不用NAT的方式下同所有容器通信,反之亦然。
(3)容器的地址和别人看到的地址是同一个地址。
这些基本要求意味着并不是只要两台机器都运行Docker,Kubernetes就可以工作了。具体的集群网络实现必须满足上述基本要求,原生的Docker网络目前还不能很好地支持这些要求。
7.7 Kubernetes网络策略
为了实现
细粒度的容器间网络访问隔离策略,Kubernetes从1.3版本开始,由SIG-Network小组主导研发了Network Policy机制,目前已升级为networking.k8s.io/v1稳定版本。
Network Policy的主要功能是对Pod间的网络通信进行限制和准入控制,
设置方式为将Pod的Label作为查询条件,设置允许访问或禁止访问的客户端Pod列表。查询条件可以作用于Pod和Namespace级别。
为了使用Network Policy, Kubernetes引入了一个新的资源对象NetworkPolicy,供用户设置Pod间网络访问的策略。但仅定义一个网络策略是无法完成实际的网络隔离的,还需要一个策略控制器(PolicyController)进行策略的实现。
策略控制器由第三方网络组件提供,目前Calico, Cilium, Kube-router, Romana, Weave Net等开源项目均支持网络策略的实现。Network Policy的工作原理如图
policy controller需要实现一个API Listener,监听用户设置的NetworkPolicy定义,并将网络访问规则通过各Node的Agent进行实际设置(Agent则需要通过CNI网络插件实现)
7.7.1 网络策略配置说明
网络策略的设置主要用于对目标Pod的网络访问进行限制,在默认·情况下对所有Pod都是允许访问的,在设置了指向Pod的NetworkPolicy网络策略之后,到Pod的访问才会被限制。
1 | apiVersion: networking.k8s.io/v1 |
7.7.2在Namespace级别设置默认的网络策略
在Namespace级别还可以设置一些默认的全局网络策略,以方便管理员对整个Namespace进行统一的网络策略设置。
默认拒绝所有入站流量
1 | apiVersion: networking.k8s.io/v1 |
默认允许所有入站流量
1 | apiVersion: networking.k8s.io/v1 |
默认拒绝所有出站流量
1 | apiVersion: networking.k8s.io/v1 |
默认允许所有出站流量
1 | apiVersion: networking.k8s.io/v1 |
默认拒绝所有入口和所有出站流量
1 | apiVersion: networking.k8s.io/v1 |
7.7.3 NetworkPolicy的发展
作为一个稳定特性,
SCTP支持默认是被启用的。 要在集群层面禁用SCTP,你(或你的集群管理员)需要为API服务器指定--feature-gates=SCTPSupport=false,… 来禁用SCTPSupport特性门控。 启用该特性门控后,用户可以将NetworkPolicy的protocol字段设置为SCTP(不同版本略有区别)
10.12 Helm:Kubernetes应用包管理工具
复杂的应用中间件,在
Kubernetes上进行容器化部署并非易事,通常需要先研究Docker镜像的运行需求、环境变量等内容,并能为这些容器定制存储、网络等设置,最后设计和编写Deployment. ConfigMap. Service及Ingress等相关YAML配置文件,再提交给Kubernetes部署。这些复杂的过程将逐步被Helm应用包管理工具实现。
10.12.1 Helm概述
Helm是一个由CNCF孵化和管理的项目,用于对需要在Kubernetes上部署的复杂应用进行定义、安装和更新。Helm以Chart的方式对应用软件进行描述,可以方便地创建、版本化、共享和发布复杂的应用软件。
10.12.2 Helm的主要概念
Helm的主要概念如下。
Chart:一个Helm包,其中包含运行一个应用所需要的工具和资源定义,还可能包含Kubernetes集群中的服务定义,类似于Homebrew中的formula, APT中的dpkg或者Yum中的RPM文件。
Release: 在Kubernetes集群上运行的一个Chart实例。在同一个集群上,一个Chart可以被安装多次。例如有一个MySQL Chart。
Repository:用于存放和共享Chart仓库。**简单来说, Helm整个系统的主要任务就是,在仓库中查找需要的Chart,然后将Chart以Release的形式安装到Kubernetes集群中。**
10.12.4 Helm的常见用法
搜索Chart,安装Chart,自定义Chart配置、更新或回滚Release、删除Release、创建自定义Chart、搭建私有仓库等。
第11章 Trouble Shooting指导
Kubernetes集群中常见问题的排查方法进行说明
为了跟踪和发现在Kubernetes集群中运行的容器应用出现的问题,我们常用如下查错方法。
(1)查看Kubernetes对象的当前运行时信息,特别是与对象关联的Event事件。这些事件记录了相关主题、发生时间、最近发生时间、发生次数及事件原因等,对排查故障非常有价值。通过查看对象的运行时数据,我们还可以发现参数错误、关联错误、状态异常等明显问题。由于在Kubernetes中多种对象相互关联,因此这一步可能会涉及多·个相关对象的排查问题。
(2)对于服务、容器方面的问题,可能需要深入容器内部进行故障诊断,此时可以通过查看容器的运行日志来定位具体问题。
(3)对于某些复杂问题,例如Pod调度这种全局性的问题,可能需要结合集群中每个节点上的Kubernetes服务日志来排查。比如搜集Master上的kube-apiserver, kube-schedule, kube-controler-manager服务日志,以及各个Node上的kubelet, kube-proxy服务日志.
11.1查看系统Event
在Kubernetes集群中创建Pod后,我们可以通过kubectl get pods命令查看Pod列表,但通过该命令显示的信息有限。Kubernetes提供了kubectl describe pod命令来查看一个Pod的详细信息,例如:
通过kubectl describe pod命令,可以显示Pod创建时的配置定义、状态等信息,还可以显示与该Pod相关的最近的Event事件,事件信息对于查错非常有用。
如果某个Pod一直处于Pending状态,我们就可以通过kubectl describe了解具体的原因:
- 没有可用的
Node以供调度。 - 开启了
资源配额管理,但在当前调度的目标节点上资源不足。 镜像下载失败。
11.2 查看容器日志
在需要排查容器内部应用程序生成的日志时,我们可以使用kubectl logs <pod_name>命令
11.3 查看Kubernetes服务日志
如果在Linux系统上安装Kubernetes,并且使用systemd系统管理Kubernetes服务,那么systemd的journal系统会接管服务程序的输出日志。在这种环境中,可以通过使用systemd status或journalct具来查看系统服务的日志。例如,使用systemctl status命令查看kube-controller-manager服务的日志:
1 | systemctl status kubelet.service |
如果不使用systemd系统接管Kubernetes服务的标准输出,则也可以通过日志相关的启动参数来指定日志的存放目录。
Pod对象相关的问题,比如无法创建Pod, Pod启动后就停止或者Pod副本无法增加,等等。此时,可以先确定Pod在哪个节点上,然后登录这个节点,从kubelet的日志中查询该Pod的完整日志,然后进行问题排查。
对于与Pod扩容相关或者与RC相关的问题,则很可能在kube-controller-manager及kube-scheduler的日志中找出问题的关键点。
kube-proxy经常被我们忽视,因为即使它意外停止, Pod的状态也是正常的,但会导致某些服务访问异常。这些错误通常与每个节点上的kube-proxy服务有着密切的关系。遇到这些问题时,首先要排查kube-proxy服务的日志,同时排查防火墙服务,要特别留意在防火墙中是否有人为添加的可疑规则。
11.4常见问题
11.4.1 由于无法下载pause镜像导致Pod一直处于Pending状态
11.4.2 Pod创建成功,但RESTARTS数量持续增加
容器的启动命令不能保持在前台运行。
11.4.3 通过服务名无法访问服务
在Kubernetes集群中应尽量使用服务名访问正在运行的微服务,但有时会访问失败。由于服务涉及服务名的DNS域名解析、kube-proxy组件的负载分发、后端Pod列表的状态等,所以可通过以下几方面排查问题。
1.查看Service的后端Endpoint是否正常
可以通过kubectl get endpoints <service name>命令查看某个服务的后端Endpoint列表,如果列表为空,则可能因为:
Service的Label Selector与Pod的Label不匹配,沒有相关的pod可以提供能力- 后端
Pod一直没有达到Ready状态(通过kubectl get pods进一步查看Pod的状态) - **Service的targetPort端口号与Pod的containerPort不一致等**。即容器暴露的端口不是SVC暴露的端口,需要使用targetPort来转发
2·查看Service的名称能否被正确解析为ClusterIP地址
可以通过在客户端容器中ping Service的ClusterlP地址,则说明DNS服务能够正确解析Service的名称;如果不能得到Service的ClusterlP地址,则可能是因为Kubernetes集群的DNS服务工作异常。
3·查看kube-proxy的转发规则是否正确
我们可以将kube-proxy服务设置为IPVS或iptables负载分发模式。
对于
IPVS负载分发模式,可以通过ipvsadm工具查看Node上的IPVS规则,查看是否正确设置Service ClusterlP的相关规则。对于
iptables负载分发模式,可以通过查看Node上的iptables规则,查看是否正确设置Service ClusterlP的相关规则。
11.5 寻求帮助
| 网站和社区 |
|---|
Kubernetes官网中监控、记录和调试相关问题: https://kubernetes.io/docs/tasks/debug-application-cluster/ |
 |
Kubernetes官方论坛: https://discuss.kubernetes.io/(这个需要科学上网) |
 |
GitHub库关于Kubernetes问题列表:https://github.com/kubernetes/kubernetes/issues |
 |
StackOverflow网站上关于Kubernetes的问题讨论:https://stackoverflow.com/questions/tagged/kubernetes |
 |
Kubernetes Slack聊天群组: https://kubernetes.slack.com/(需要谷歌账号) |
《Kubernetes权威指南:从Docker到Kubernetes实践全接触》读书笔记
https://liruilongs.github.io/2021/08/27/K8s/读书笔记/《Kubernetes权威指南-从Docker到Kubernetes实践全接触》读书笔记/
1.K8s 集群高可用master节点ETCD全部挂掉如何恢复?
2.K8s 集群高可用master节点故障如何恢复?
3.K8s 镜像缓存管理 kube-fledged 认知
4.K8s集群故障(The connection to the server <host>:<port> was refused - did you specify the right host or port)解决
5.关于 Kubernetes中Admission Controllers(准入控制器) 认知的一些笔记
6.K8s Pod 创建埋点处理(Mutating Admission Webhook)
7.关于AI(深度学习)相关项目 K8s 部署的一些思考
8.K8s Pod 安全认知:从openshift SCC 到 PSP 弃用以及现在的 PSA

