关于 Kubernetes中一些基本概念和术语笔记
一个不欣赏自己的人,是难以快乐的。——-三毛
写在前面
- 学习K8s,所以整理记忆
- 大部分部分内容来源于
《Kubernetes权威指南:从Docker到Kubernetes实践全接触》第一章,感兴趣小伙伴可以支持作者一波
一个不欣赏自己的人,是难以快乐的。——-三毛
一、简述
Kubernetes中的大部分概念如Node, Pod,Replication Controller, Service等都可以看作一种“资源对象”,几乎所有的资源对象都可以通过Kubernetes提供的kubect工具(或者API编程调用)执行增、删、改、查等操作并将其保存在etcd中持久化存储。从这个角度来看, Kubernetes其实是一个高度自动化的资源控制系统,它通过`跟踪对比etcd库里保存的“资源期望状态”与当前环境中的“实际资源状态”的差异来实现自动控制和自动纠错的高级功能。
K8s中相关资源:随版本变化
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-pod-create] |
| NAME(名字) | SHORTNAMES(简称) | APIVERSION(版本) | NAMESPACED(命名空间隔离) | KIND(种类) |
|---|---|---|---|---|
| bindings | v1 | true | Binding | |
| componentstatuses | cs | v1 | false | ComponentStatus |
| configmaps | cm | v1 | true | ConfigMap |
| endpoints | ep | v1 | true | Endpoints |
| events | ev | v1 | true | Event |
| limitranges | limits | v1 | true | LimitRange |
| namespaces | ns | v1 | false | Namespace |
| nodes | no | v1 | false | Node |
| persistentvolumeclaims | pvc | v1 | true | PersistentVolumeClaim |
| persistentvolumes | pv | v1 | false | PersistentVolume |
| pods | po | v1 | true | Podpodtemplates |
| replicationcontrollers | rc | v1 | true | ReplicationController |
| resourcequotas | quota | v1 | true | ResourceQuota |
| secrets | v1 | true | Secret | |
| serviceaccounts | sa | v1 | true | ServiceAccount |
| services | svc | v1 | true | Service |
| mutatingwebhookconfigurations | admissionregistration.k8s.io/v1 | false | MutatingWebhookConfiguration | |
| validatingwebhookconfigurations | admissionregistration.k8s.io/v1 | false | ValidatingWebhookConfiguration | |
| customresourcedefinitions | crd,crds | apiextensions.k8s.io/v1 | false | CustomResourceDefinition |
| apiservices | apiregistration.k8s.io/v1 | false | APIService | |
| controllerrevisions | apps/v1 | true | ControllerRevision | |
| daemonsets | ds | apps/v1 | true | DaemonSet |
| deployments | deploy | apps/v1 | true | Deployment |
| replicasets | rs | apps/v1 | true | ReplicaSet |
| statefulsets | sts | apps/v1 | true | StatefulSet |
| tokenreviews | authentication.k8s.io/v1 | false | TokenReview | |
| localsubjectaccessreviews | authorization.k8s.io/v1 | true | LocalSubjectAccessReview | |
| selfsubjectaccessreviews | authorization.k8s.io/v1 | false | SelfSubjectAccessReview | |
| selfsubjectrulesreviews | authorization.k8s.io/v1 | false | SelfSubjectRulesReview | |
| subjectaccessreviews | authorization.k8s.io/v1 | false | SubjectAccessReview | |
| horizontalpodautoscalers | hpa | autoscaling/v1 | true | HorizontalPodAutoscaler |
| cronjobs | cj | batch/v1 | true | CronJob |
| jobs | batch/v1 | true | Jobcertificatesigningrequests | |
| leases | coordination.k8s.io/v1 | true | Lease | |
| bgpconfigurations | crd.projectcalico.org/v1 | false | BGPConfiguration | |
| bgppeers | crd.projectcalico.org/v1 | false | BGPPeer | |
| blockaffinities | crd.projectcalico.org/v1 | false | BlockAffinity | |
| clusterinformations | crd.projectcalico.org/v1 | false | ClusterInformation | |
| felixconfigurations | crd.projectcalico.org/v1 | false | FelixConfiguration | |
| globalnetworkpolicies | crd.projectcalico.org/v1 | false | GlobalNetworkPolicy | |
| globalnetworksets | crd.projectcalico.org/v1 | false | GlobalNetworkSet | |
| hostendpoints | crd.projectcalico.org/v1 | false | HostEndpoint | |
| ipamblocks | crd.projectcalico.org/v1 | false | IPAMBlock | |
| ipamconfigs | crd.projectcalico.org/v1 | false | IPAMConfig | |
| ipamhandles | crd.projectcalico.org/v1 | false | IPAMHandle | |
| ippools | crd.projectcalico.org/v1 | false | IPPool | |
| kubecontrollersconfigurations | crd.projectcalico.org/v1 | false | KubeControllersConfiguration | |
| networkpolicies | crd.projectcalico.org/v1 | true | NetworkPolicy | |
| networksets | crd.projectcalico.org/v1 | true | NetworkSet | |
| endpointslices | discovery.k8s.io/v1 | true | EndpointSlice | |
| events | ev | events.k8s.io/v1 | true | Event |
| flowschemas | flowcontrol.apiserver.k8s.io/v1beta1 | false | FlowSchema | |
| prioritylevelconfigurations | flowcontrol.apiserver.k8s.io/v1beta1 | false | PriorityLevelConfiguration | |
| nodes | metrics.k8s.io/v1beta1 | false | NodeMetrics | |
| pods | metrics.k8s.io/v1beta1 | true | PodMetrics | |
| ingressclasses | networking.k8s.io/v1 | false | IngressClass | |
| ingresses | ing | networking.k8s.io/v1 | true | Ingress |
| networkpolicies | netpol | networking.k8s.io/v1 | true | NetworkPolicy |
| runtimeclasses | node.k8s.io/v1 | false | RuntimeClass | |
| poddisruptionbudgets | pdb | policy/v1 | true | PodDisruptionBudget |
| podsecuritypolicies | psp | policy/v1beta1 | false | PodSecurityPolicy |
| clusterrolebindings | rbac.authorization.k8s.io/v1 | false | ClusterRoleBinding | |
| clusterroles | rbac.authorization.k8s.io/v1 | false | ClusterRole | |
| rolebindings | rbac.authorization.k8s.io/v1 | true | RoleBinding | |
| roles | rbac.authorization.k8s.io/v1 | true | Role | |
| priorityclasses | pc | scheduling.k8s.io/v1 | false | PriorityClass |
| csidrivers | storage.k8s.io/v1 | false | CSIDriver | |
| csinodes | storage.k8s.io/v1 | false | CSINode | |
| csistoragecapacities | storage.k8s.io/v1beta1 | true | CSIStorageCapacity | |
| storageclasses | sc | storage.k8s.io/v1 | false | StorageClass |
| volumeattachments | storage.k8s.io/v1 | false | VolumeAttachment |
二、Kubernetes集群的两种管理角色: Master和Node
Master和Node |
|---|
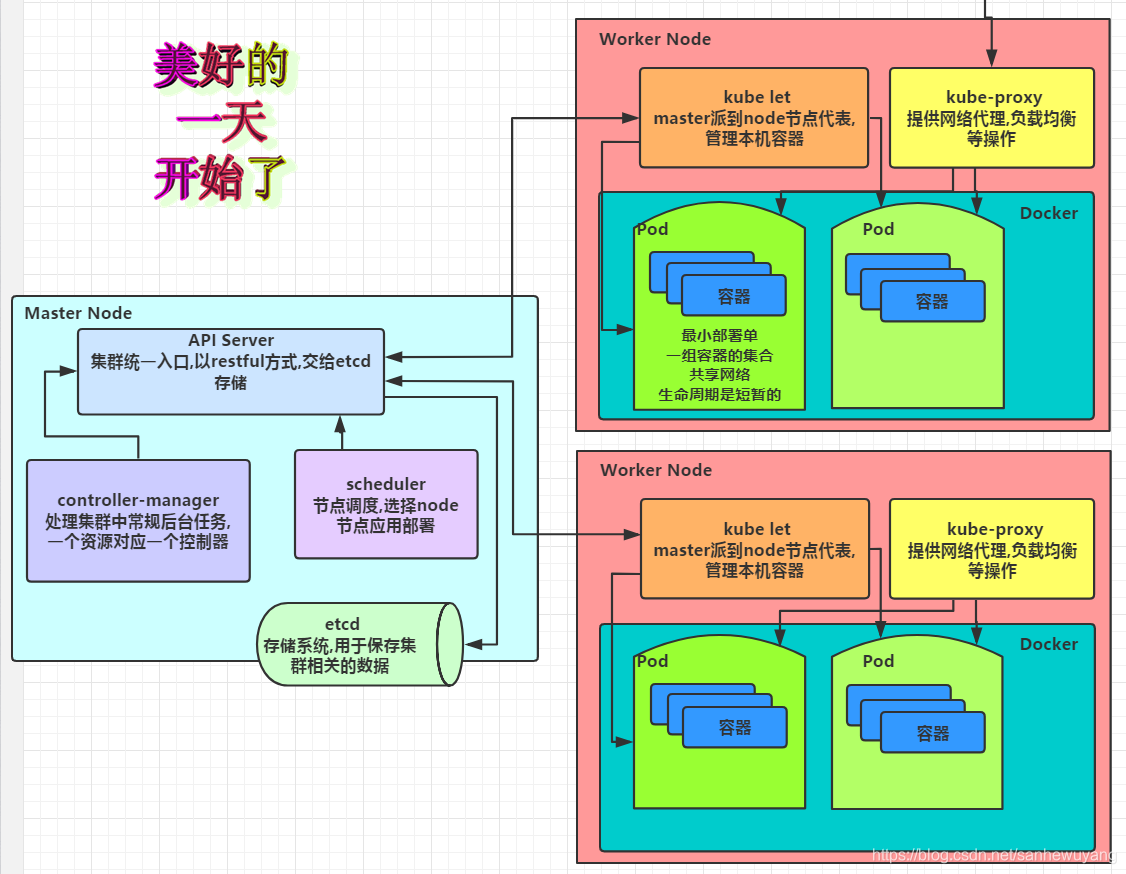 |
1、Master角色
Kubernetes里的Master指的是 集群控制节点,每个Kubernetes集群里需要有一个Master节点来负责整个集群的管理和控制,基本上Kubernetes的所有控制命令都发给它,它来负责具体的执行过程,我们后面执行的所有命令基本都是在Master节点上运行的。
Master节点通常会占据一个独立的服务器(高可用部署建议用3台服务器),其主要原因是它太重要了,是整个集群的“首脑”,如果宕机或者不可用,那么对集群内容器应用的管理都将失效。Master节点上运行着以下一组关键进程。
| Master节点上关键进程 | – |
|---|---|
Kubernetes API Server (kube-apiserver) |
提供了HTTP Rest接口的关键服务进程,是Kubernetes里所有资源的增、删、改、查等操作的唯一入口,也是集群控制的入口进程。 |
Kubernetes Controller Manager (kube-controller-manager) |
Kubernetes里所有资源对象的自动化控制中心,可以理解为资源对象的“大总管”。 |
Kubernetes Scheduler (kube-scheduler) |
负责资源调度(Pod调度)的进程,相当于公交公司的“调度室”。 |
etcd |
在Master节点上还需要启动一个etcd服务,因为Kubernetes里的所有资源对象的数据全部是保存在etcd中的。 |
除了Master, Kubernetes集群中的其他机器被称为Node节点
2、Node角色
在较早的版本中也被称为Miniono与Master一样, Node节点可以是一台物理主机,也可以是一台虚拟机。 Node节点才是Kubermetes集群中的工作负载节点,每个Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机时,其上的工作负载会被Master自动转移到其他节点上去。
每个Node节点上都运行着以下一组关键进程。
| 每个Node节点上都运行关键进程 | – |
|---|---|
kubelet |
负责Pod对应的容器的创建、启停等任务,同时与Master节点密切协作,实现集群管理的基本功能。 |
kube-proxy |
实现Kubernetes Service的通信与负载均衡机制的重要组件。) |
Docker Engine |
(docker): Docker引擎,负责本机的容器创建和管理工作。 |
Node节点可以在运行期间动态增加到Kubernetes集群中,前提是这个节点上已经正确安装、配置和启动了上述关键进程,**在默认情况下kubelet会向Master注册自己,这也是Kubernetes推荐的Node管理方式**。
一旦Node被纳入集群管理范围, kubelet进程就会定时向Master节点汇报自身的情报,例如操作系统、Docker版本、机器的CPU和内存情况,以及当前有哪些Pod在运行等,这样Master可以获知每个Node的资源使用情况,并实现高效均衡的资源调度策略。而某个Node超过指定时间不上报信息时,会被Master判定为“失联”, Node的状态被标记为不可用(Not Ready),随后Master会触发“工作负载大转移”的自动流程。
查看集群中的Node节点和节点的详细信息
1 | ┌──[root@vms81.liruilongs.github.io]-[~] |
1 | ┌──[root@vms81.liruilongs.github.io]-[~] |
总结一下,我们要操作k8s,在管理节点那我们怎么操作,我们通过kube-apiserver来接受用户的请求,通过kubu-scheduler来负责资源的调度,是使用work1计算节点来处理还是使用work2计算节点来处理,然后在每个节点上要运行一个代理服务kubelet,用来控制每个节点的操作,但是每个节点的状态,是否健康我们不知道,这里我们需要kube-controller-manager
3、 Pod资源对象
Pod是Kubernetes的最重要也最基本的概念,
每个Pod都有一个特殊的被称为“根容器”的Pause容器。Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器,每个Pod还包含一个或多个紧密相关的用户业务容器。
Pause容器
为什么Kubernetes会设计出一个全新的Pod的概念并且Pod有这样特殊的组成结构? |
|---|
原因之一:在一组容器作为一个单元的情况下,我们难以对“整体”简单地进行判断及有效地进行行动。引入业务无关并且不易死亡的Pause容器作为Pod的根容器,以它的状态代表整个容器组的状态,就简单、巧妙地解决了这个难题。 |
原因之二: Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂接的Volume,这样既简化了密切关联的业务容器之间的通信问题,也很好地解决了它们之间的文件共享问题。 |
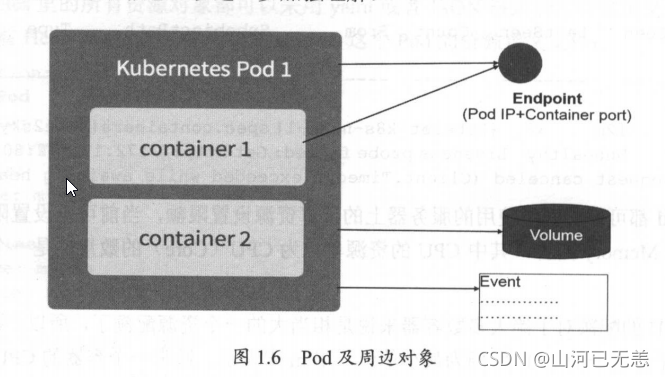
Pod IP
Kubernetes 为每个Pod都分配了唯一的IP地址,称之为Pod IP,一个Pod里的多个容器共享Pod IP地址。 Kuberetes要求底层网络支持集群内任意两个Pod之间的TCP/P直接通信,这通常采用虚拟二层网络技术来实现(链路层网桥),
在
Kubernetes里,一个Pod里的容器与另外主机上的Pod容器能够直接通信。
普通的Pod及静态Pod (Static Pod)
Pod其实有两种类型:普通的Pod及静态Pod (Static Pod),如果使用kubeadm的方式部署,静态pod在node节点和master节点创建略有不同
| Pod两种类型 | 描述 |
|---|---|
静态Pod (Static Pod) |
并 不存放在Kubernetes的etcd存储 里,而是存放在某个具体的Node上的一个具体文件中,并且只在此Node上启动运行。 |
普通的Pod |
一旦被创建,就会被放入到etcd中存储,随后会被Kubernetes Masten调度到某个具体的Node上并进行绑定(Binding),随后该Pod被对应的Node上的kubelet进程实例化成一组相关的Docker容器并启动起来。 |
正常情况下,pod是在master上统一管理的,所谓静态pod就是,即不是由master上创建调度的,是属于node自身特的pod,在node上只要启动kubelet之后,就会自动的创建的pod。这里理解的话,结合java静态熟悉,静态方法理解,即的node节点初始化的时候需要创建的一些pod
比如 kubeadm的安装k8s的话,所以的服务都是通过容器的方式运行的。相比较二进制的方式方便很多,这里的话,那么涉及到master节点的相关组件在没有k8s环境时是如何运行,构建master节点的,这里就涉及到静态pod的问题。
在默认情况下,当Pod里的某个容器停止时,Kubernetes会自动检测到这个问题并且重新启动这个Pod (重启Pod里的所有容器),如果Pod所在的Node宕机,则会将这个Node上的所有Pod重新调度到其他节点上.
| – |
|---|
 |
Kubernetes里的所有资源对象都可以采用yaml或者JSON格式的文件来定义或描述,下面是我们在之前Hello World例子里用到的myweb这个Pod的资源定义文件:
1 | apiVersion: v1 |
Kubernetes的Event概念, Event是一个事件的记录,记录了事件的最早产生时间、最后重现时间、重复次数、发起者、类型,以及导致此事件的原因等众多信息。Event通常会关联到某个具体的资源对象上,是排查故障的重要参考信息,
Pod同样有Event记录,当我们发现某个Pod迟迟无法创建时,可以用kubectl describe pod xxxx来查看它的描述信息,用来定位问题的原因
在Kubernetes里,一个计算资源进行配额限定需要设定以下两个参数。
| 计算资源进行配额限定 |
|---|
| Requests:该资源的最小申请量,系统必须满足要求。 |
| Limits:该资源最大允许使用的量,不能被突破,当容器试图使用超过这个量的资源时,可能会被Kubernetes Kill并重启。 |
通常我们会把Request设置为一个比较小的数值,符合容器平时的工作负载情况下的资源需求,而把Limit设置为峰值负载情况下资源占用的最大量。
比如下面这段定义,表明MysQL容器申请最少0.25个CPU及64MiB内存,在运行过程中MySQL容器所能使用的资源配额为0.5个CPU及128MiB内存:
1 | .... |
Pod Pod 周边对象的示意图
4 、Lable 标签
Label是Kubernetes系统中另外一个核心概念。一个Label是一个key-value的键值对。其中key与value由用户自己指定。
Label可以附加到各种资源对象上,例如Node、Pod、Service、RC等,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意数量的资源对象上去, Label通常在资源对象定义时确定,也可以在对象创建后动态添加,或者删除。
可以通过给指定的资源对象捆绑一个或多个不同的Label来实现多维度的资源分组管理功能,以便于灵活、方便地进行资源分配、调度、配置、部署等管理工作。
例如:部署不同版本的应用到不同的环境中;或者监控和分析应用(日志记录、监控、告警)等。一些常用的Label示例如下。
1 | 版本标签: "release" : "stable", "release":"canary".... |
可以通过多个Label Selector表达式的组合实现复杂的条件选择,多个表达式之间用“,”进行分隔即可,几个条件之间是“AND”的关系,即同时满足多个条件,比如下面的例子:
1 | name=标签名 |
1 | apiVersion: v1 |
新出现的管理对象如Deployment, ReplicaSet, DaemonSet和Job则可以在Selector中使用基于集合的筛选条件定义,例如:
1 | selector: |
matchLabels用于定义一组Label,与直接写在Selector中作用相同; matchExpressions用于定义一组基于集合的筛选条件,可用的条件运算符包括: In, NotIn, Exists和DoesNotExist.
如果同时设置了matchLabels和matchExpressions,则两组条件为"AND"关系,即所有条件需要同时满足才能完成Selector的筛选。
Label Selector在Kubernetes中的重要使用场景有以下几处:
kube-controller进程通过资源对象RC上定义的Label Selector来筛选要监控的Pod副本的数量,从而实现Pod副本的数量始终符合预期设定的全自动控制流程
kube-proxy进程通过Service的Label Selector来选择对应的Pod, 自动建立起每个Service到对应Pod的请求转发路由表,从而实现Service的智能负载均衡机制
通过对某些Node定义特定的Label,并且在Pod定义文件中使用NodeSelector这种标签调度策略, kube-scheduler进程可以实现Pod “定向调度”的特性。
1 | apiVersion: v1 |
5、 Replication Controller
RC是Kubernetes系统中的核心概念之一,简单来说,它其实是定义了一个期望的场景,即声明某种Pod的副本数量在任意时刻都符合某个预期值,所以RC的定义包括如下几个部分。
| RC的定义 |
|---|
Pod 期待的副本数(replicas) |
用于筛选目标Pod的Label Selector |
当Pod的副本数量小于预期数量时,用于创建新Pod的Pod模板(template)。 |
下面是一个完整的RC定义的例子,即确保拥有tier-frontend标签的这个Pod (运行Tomcat容器)在整个Kubernetes集群中始终只有一个副本:
1 | apiVersion: v1 |
当我们定义了一个RC并提交到Kubernetes集群中以后, Master节点上的Controller Manager组件就得到通知,定期巡检系统中当前存活的目标Pod,并确保目标Pod实例的数量刚好等于此RC的期望值,如果有过多的Pod副本在运行,系统就会停掉一些Pod,否则系统就会再自动创建一些Pod
通过RC, Kubernetes实现了用户应用集群的高可用性,并且大大减少了系统管理员在传统IT环境中需要完成的许多手工运维工作(如主机监控脚本、应用监控脚本、故障恢复脚本等)
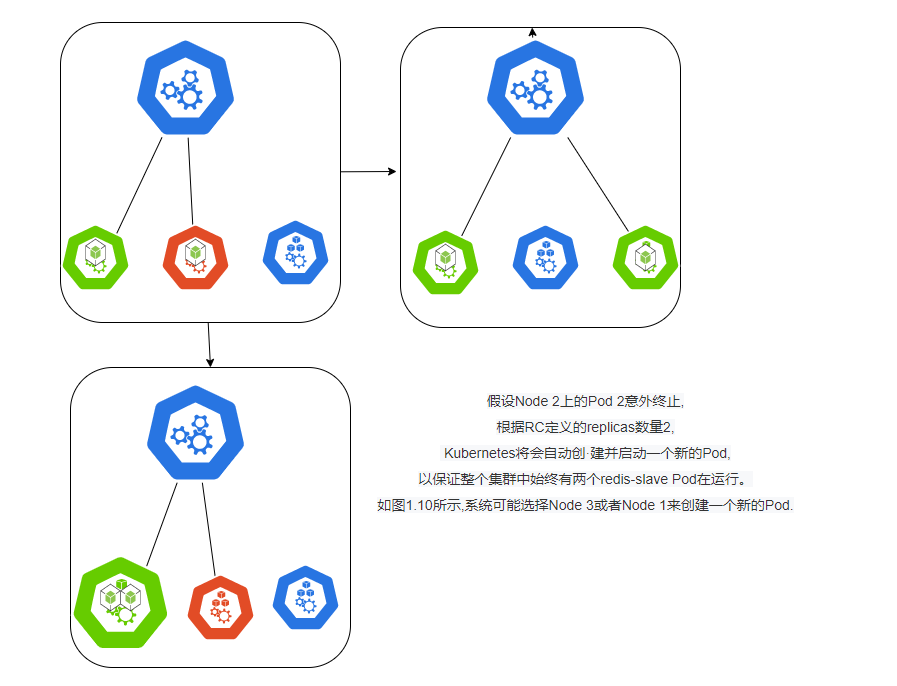
下面我们以3个Node节点的集群为例,说明Kubernetes如何通过RC来实现Pod副本数量自动控制的机制。假如我们的RC里定义redis-slave这个Pod需要保持3个副本,系统将可能在其中的两个Node上创建Pod,图1.9描述了在两个Node上创建redis-slave Pod的情形。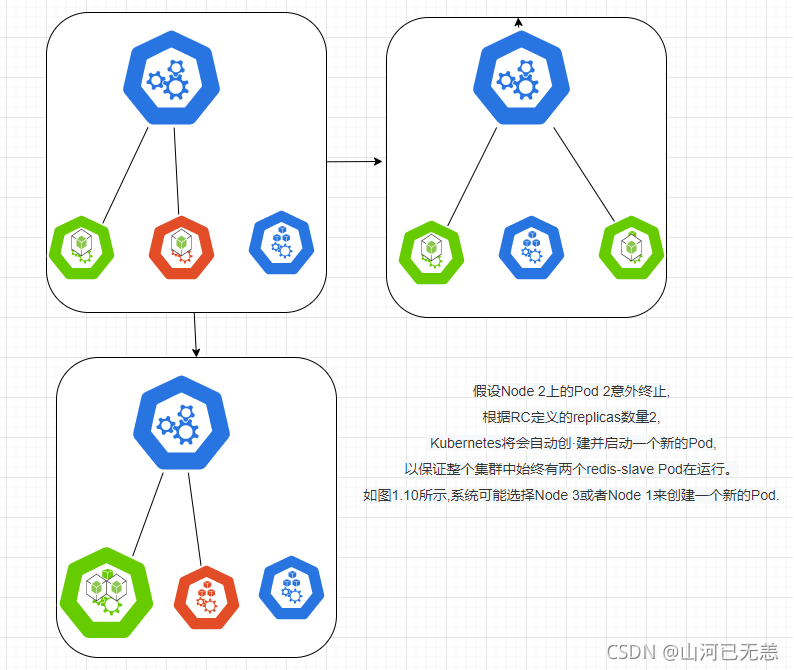
在运行时,我们可以通过 修改RC的副本数量,来实现Pod的动态缩放(Scaling)功能,这可以通过执行kubectl scale命令来一键完成:
1 | kubectl scale rc redsi-slave --replicas=3 |
需要注意的是,删除RC并不会影响通过该RC已创建好的Pod,为了删除所有Pod,可以设置replicas的值为0,然后更新该RC。另外, kubectl提供了stop和delete命令来一次性删除RC和RC控制的全部Pod。
应用升级时,通常会通过Build一个新的Docker镜像,并用新的镜像版本来替代旧的版本的方式达到目的。在系统升级的过程中,我们希望是平滑的方式,比如当前系统中10个对应的旧版本的Pod,最佳的方式是旧版本的Pod每次停止一个,同时创建一个新版本的Pod,在整个升级过程中,此消彼长,而运行中的Pod数量始终是10个,通过RC的机制, Kubernetes很容易就实现了这种高级实用的特性,被称为“滚动升级” (Rolling Update)
6、 Deployment
Deployment是Kubernetes v1.2引入的新概念,引入的目的是为了更好地解决Pod的编排问题。
**Deployment相对于RC的一个最大升级是我们可以随时知道当前Pod “部署”的进度**。实际上由于一个Pod的创建、调度、绑定节点及在目标Node上启动对应的容器这一完整过程需要一定的时间,所以我们期待系统启动N个Pod副本的目标状态,实际上是一个连续变化的“部署过程”导致的最终状态。
Deployment的典型使用场景有以下几个。
| Deployment的典型使用场景 |
|---|
| 创建一个Deployment对象来生成对应的Replica Set并完成Pod副本的创建过程。 |
| 检查Deployment的状态来看部署动作是否完成(Pod副本的数量是否达到预期的值) |
| 更新Deployment以创建新的Pod (比如镜像升级)。 |
| 如果当前Deployment不稳定,则回滚到一个早先的Deployment版本。 |
| 暂停Deployment以便于一次性修改多个PodTemplateSpec的配置项,之后再恢复Deployment,进行新的发布。 |
| 扩展Deployment以应对高负载。 |
| 查看Deployment的状态,以此作为发布是否成功的指标。 |
| 清理不再需要的旧版本ReplicaSets。 |
Deployment的定义与Replica Set的定义很类似,除了API声明与Kind类型等有所区别:
1 | apiversion: extensions/vlbetal apiversion: v1 |
创建一个 tomcat-deployment.yaml Deployment 描述文件:
1 | apiVersion: extensions/v1betal |
运行如下命令创建 Deployment:
1 | kubectl create -f tomcat-deploment.yaml |
对上述输出中涉及的数量解释如下。
| 数量 | 解释 |
|---|---|
DESIRED |
Pod副本数量的期望值,即Deployment里定义的Replica. |
CURRENT |
当前Replica的值,实际上是Deployment所创建的Replica Set里的Replica值,这个值不断增加,直到达到DESIRED为止,表明整个部署过程完成。 |
UP-TO-DATE |
最新版本的Pod的副本数量,用于指示在滚动升级的过程中,有多少个Pod副本已经成功升级。 |
AVAILABLE |
当前集群中可用的Pod副本数量,即集群中当前存活的Pod数量。 |
运行下述命令查看对应的Replica Set,我们看到它的命名与Deployment的名字有关系:
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible] |
7、 Horizontal Pod Autoscaler
**HPA与之前的RC、 Deployment一样,也属于一种Kubernetes资源对象**。通过 追踪分析RC控制的所有目标Pod的负载变化情况,来确定是否需要针对性地调整目标Pod的副本数,这是HPA的实现原理 。当前, HPA可以有以下两种方式作为Pod负载的度量指标。
| Horizontal Pod Autoscaler |
|---|
| CPUUtilizationPercentage. |
| 应用程序自定义的度量指标,比如服务在每秒内的相应的请求数(TPS或QPS) |
1 | apiversion: autoscaling/v1 |
CPUUtilizationPercentage是一个算术平均值,即目标Pod所有副本自身的CPU利用率的平均值。一个Pod自身的CPU利用率是该Pod当前CPU的使用量除以它的Pod Request的值,比,如我们定义一个Pod的Pod Request为0.4,而当前Pod的CPU使用量为0.2,则它的CPU使用率为50%
根据上面的定义,我们可以知道这个HPA控制的目标对象为一个名叫php-apache Deployment里的Pod副本,当这些Pod副本的CPUUtilizationPercentage的值超过90%时会触发自动动态扩容行为,扩容或缩容时必须满足的一个约束条件是Pod的副本数要介于1与10之间。
除了可以通过直接定义yaml文件并且调用kubectrl create的命令来创建一个HPA资源对象的方式,我们还能通过下面的简单命令行直接创建等价的HPA对象:
1 | kubectl autoscale deployment php-apache --cpu-percent=90--min-1 --max=10 |
8、 StatefulSet
在Kubernetes系统中, Pod的管理对象RC, Deployment, DaemonSet和Job都是面向无状态的服务。 但现实中有很多服务是有状态的,特别是一些复杂的中间件集群,例如MysQL集·群、MongoDB集群、ZooKeeper集群等,这些应用集群有以下一些共同点:
| 共同點 |
|---|
| 每个节点都有固定的身份ID,通过这个ID,集群中的成员可以相互发现并且通信。 |
| 集群的规模是比较固定的,集群规模不能随意变动。 |
| 集群里的每个节点都是有状态的,通常会持久化数据到永久存储中。 |
| 如果磁盘损坏,则集群里的某个节点无法正常运行,集群功能受损 |
如果用
RC/Deployment控制Pod副本数的方式来实现上述有状态的集群,则我们会发现第1点是无法满足的,因为Pod的名字是随机产生的,Pod的IP地址也是在运行期才确定且可能有变动的,我们事先无法为每个Pod确定唯一不变的ID,
为了能够在其他节点上恢复某个失败的节点,这种集群中的Pod需要挂接某种共享存储,为了解决这个问题, Kubernetes从v1.4版本开始引入了PetSet这个新的资源对象,并且在v1.5版本时更名为StatefulSet, StatefulSet从本质上来说,可以看作DeploymentRC的一个特殊变种,它有如下一些特性。)
| 特性 |
|---|
StatefulSet里的每个Pod都有稳定、唯一的网络标识,可以用来发现集群内的其他成员。假设StatefulSet的名字叫kafka,那么第1个Pod 叫 kafka-0,第2个叫kafk-1,以此类推。) |
StatefulSet控制的Pod副本的启停顺序是受控的,操作第n个Pod时,前n-1个Pod已经是运行且准备好的状态) |
StatefulSet里的Pod采用稳定的持久化存储卷,通过PV/PVC来实现,删除Pod时默认不会删除与StatefulSet相关的存储卷(为了保证数据的安全)。 |
statefulSet除了要与PV卷捆绑使用以存储Pod的状态数据,还要与Headless Service配合使用,即在每个StatefulSet的定义中要声明它属于哪个Headless Service. Headless Service与普通Service的关键区别在于,它没有Cluster IP,如果解析Headless Service的DNS域名,则返回的是该Service对应的全部Pod的Endpoint列表。StatefulSet在Headless Service的基础上又为StatefulSet控制的每个Pod实例创建了一个DNS域名,这个域名的格式为:
1 | $(podname).$(headless service name) |
9、 Service (服务)
Service也是Kubernetes里的最核心的资源对象之一, **Kubernetes里的每个Service其实就是我们经常提起的微服务架构中的一个“微服务”,之前我们所说的Pod, RC等资源对象其实都是为这节所说的“服务”-Kubernetes Service作“嫁衣”的。Pod,RC与Service的逻辑关系**。
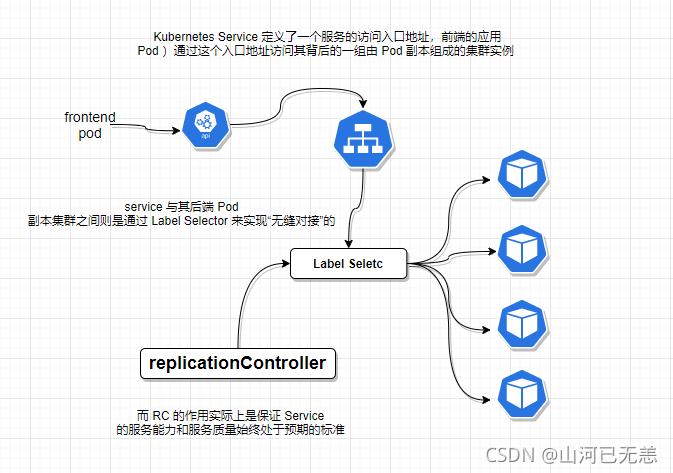
Kubernetes的Service定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口地址访问其背后的一组由Pod副本组成的集群实例, Service与其后端Pod副本集群之间则是通过Label Selector来实现“无缝对接”的。而RC的作用实际上是保证Service的服务能力和服务质量始终处干预期的标准。
每个Pod都会被分配一个单独的IP地址,而且每个Pod都提供了一个独立的Endpoint(Pod IP+ContainerPort)以被客户端访问,现在多个Pod副本组成了一个集群来提供服务.客户端如何来访问它们呢?一般的做法是部署一个负载均衡器(软件或硬件),
**Kubernetes中运行在每个Node上的kube-proxy进程其实就是一个智能的软件负载均衡器,它负责把对Service的请求转发到后端的某个Pod实例上,并在内部实现服务的负载均衡与会话保持机制**。
Kubernetes发明了一种很巧妙又影响深远的设计:
Service不是共用一个负载均衡器的IP地址,而是每个Service分配了一个全局唯一的虚拟IP地址,这个虚拟IP被称为Cluster IP,这样一来,每个服务就变成了具备唯一IP地址的“通信节点”,服务调用就变成了最基础的TCP网络通信问题。
我们知道, Pod的Endpoint地址会随着Pod的销毁和重新创建而发生改变,因为新Pod的IP地址与之前旧Pod的不同。而 **Service一旦被创建, Kubernetes就会自动为它分配一个可用的Cluster IP,而且在Service的整个生命周期内,它的Cluster IP不会发生改变**。于是,服务发现这个棘手的问题在Kubernetes的架构里也得以轻松解决:只要用Service的Name与Service的Cluster IP地址做一个DNS域名映射即可完美解决问题。
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-pod-create] |
Kubernetes Service支持多个Endpoint(端口),**在存在多个Endpoint的情况下,要求每个Endpoint定义一个名字来区分**。下面是Tomcat多端口的Service定义样例:
1 | spec: |
多端口为什么需要给每个端口命名呢?这就涉及Kubernetes的服务发现机制了
Kubernetes 的服务发现机制
| Kubernetes 的服务发现机制 |
|---|
| 最早时Kubernetes采用了Linux环境变量的方式解决这个问题,即每个Service生成一些对应的Linux环境变量(ENV),并在每个Pod的容器在启动时,自动注入这些环境变量 |
| 后来Kubernetes通过Add-On增值包的方式引入了DNS系统,把服务名作为DNS域名,这样一来,程序就可以直接使用服务名来建立通信连接了。目前Kubernetes上的大部分应用都已经采用了DNS这些新兴的服务发现机制 |
外部系统访问 Service 的问题
| Kubernetes里的“三种IP” | 描述 |
|---|---|
| Node IP | Node 节点的IP地址,Node IP是Kubernetes集群中每个节点的物理网卡的IP地址,这是一个真实存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通信,不管它们中是否有部分节点不属于这个Kubernetes集群。**这也表明了Kubernetes集群之外的节点访问Kubernetes集群之内的某个节点或者TCP/IP服务时,必须要通过Node IP进行通信**。 |
| Pod IP | Pod 的 IP 地址:Pod IP是每个Pod的IP地址,它是Docker Engine根据dockero网桥的IP地址段进行分配的,通常是一个虚拟的二层网络,前面我们说过, Kubernetes要求位于不同Node上的Pod能够彼此直接通信,所以Kubernetes里一个Pod里的容器访问另外一个Pod里的容器,就是通过Pod IP所在的虚拟二层网络进行通信的,而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出的。 |
| Cluster IP | Service 的IP地址,Cluster IP仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配IP地址(来源于Cluster IP地址池)。Cluster IP无法被Ping,因为没有一个“实体网络对象”来响应。Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备TCPIP通信的基础,并且它们属于Kubernetes集群这样一个封闭的空间,集群之外的节点如果要访问这个通信端口,则需要做一些额外的工作。在Kubernetes集群之内, Node IP网、Pod IP网与Cluster IP网之间的通信,采用的是Kubermetes自己设计的一种编程方式的特殊的路由规则,与我们所熟知的IP路由有很大的不同。 |
外部系统访问 Service,采用NodePort是解决上述问题的最直接、最有效、最常用的做法。具体做法如下,以tomcat-service为例,我们在Service的定义里做如下扩展即可:
1 | ... |
即这里我们可以通过nodePort:31002 来访问Service,NodePort的实现方式是在Kubernetes集群里的每个Node上为需要外部访问的Service开启个对应的TCP监听端口,外部系统只要用任意一个Node的IP地址+具体的NodePort端口即可访问此服务,在任意Node上运行netstat命令,我们就可以看到有NodePort端口被监听:
Service 负载均衡问题
但NodePort还没有完全解决外部访问Service的所有问题,比如负载均衡问题,假如我们的集群中有10个Node,则此时最好有一个负载均衡器,外部的请求只需访问此负载均衡器的IP地址,由负载均衡器负责转发流量到后面某个Node的NodePort上。如图
| NodePort的负载均衡 |
|---|
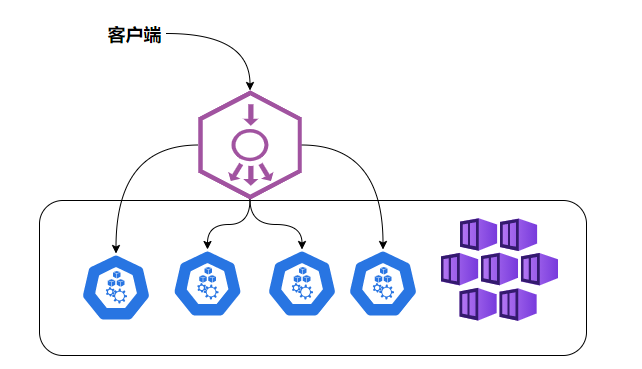 |
Load balancer组件独立于Kubernetes集群之外,通常是一个硬件的负载均衡器,或者是以软件方式实现的,例如HAProxy或者Nginx。对于每个Service,我们通常需要配置一个对应的Load balancer实例来转发流量到后端的Node上 |
Kubernetes提供了自动化的解决方案,如果我们的集群运行在谷歌的GCE公有云上,那么只要我们把Service的type-NodePort改为type-LoadBalancer,此时Kubernetes会自动创建一个对应的Load balancer实例并返回它的IP地址供外部客户端使用。 |
10、 Volume (存储卷)
Volume是Pod中能够被多个容器访问的共享目录。Kuberetes的Volume概念、用途和目的与Docker的Volume比较类似,但两者不能等价。
| Volume (存储卷) |
|---|
Kubernetes中的Volume定义在Pod上,然后被一个Pod里的多个容器挂载到具体的文件目录下; |
Kubernetes中的Volume与Pod的生命周期相同,但与容器的生命周期不相关,当容器终止或者重启时, Volume中的数据也不会丢失。 |
Kubernetes支持多种类型的Volume,例如GlusterFS, Ceph等先进的分布式文件系统。 |
Volume的使用也比较简单,在大多数情况下,我们先在Pod上声明一个Volume,然后在容器里引用该Volume并Mount到容器里的某个目录上。举例来说,我们要给之前的Tomcat Pod增加一个名字为datavol的Volume,并且Mount到容器的/mydata-data目录上,则只要对Pod的定义文件做如下修正即可(注意黑体字部分):
1 | template: |
除了可以让一个
Pod里的多个容器共享文件、让容器的数据写到宿主机的磁盘上或者写文件到网络存储中,Kubernetes的Volume还扩展出了一种非常有实用价值的功能,即
容器配置文件集中化定义与管理,这是通过ConfigMap这个新的资源对象来实现的.
Kubernetes提供了非常丰富的Volume类型,下面逐一进行说明。
1. emptyDir
**一个emptyDir Volume是在Pod分配到Node时创建的**。从它的名称就可以看出,它的初始内容为空,并且无须指定宿主机上对应的目录文件,因为这是 Kubernetes自动分配的一个目录,当Pod从Node上移除时, emptyDir中的数据也会被永久删除。emptyDir的一些用途如下。
| emptyDir的一些用途 |
|---|
| 临时空间,例如用于某些应用程序运行时所需的临时目录,且无须永久保留。 |
| 长时间任务的中间过程CheckPoint的临时保存目录。 |
| 一个容器需要从另一个容器中获取数据的目录(多容器共享目录) |
2. hostPath
hostPath为在Pod上挂载宿主机上的文件或目录,它通常可以用于以下几方面。
|容器应用程序生成的日志文件需要永久保存时,可以使用宿主机的高速文件系统进行存储。|
需要访问宿主机上Docker引擎内部数据结构的容器应用时,可以通过定义hostPath为宿主机/var/lib/docker目录,使容器内部应用可以直接访问Docker的文件系统。
在使用这种类型的Volume时,需要注意以下几点。
在不同的Node上具有相同配置的Pod可能会因为宿主机上的目录和文件不同而导致对Volume上目录和文件的访问结果不一致。)
如果使用了资源配额管理,则Kubernetes无法将hostPath在宿主机上使用的资源纳入管理。在下面的例子中使用宿主机的/data目录定义了一个hostPath类型的Volume:
1 | volumes: |
3. gcePersistentDisk
使用这种类型的Volume表示使用谷歌公有云提供的永久磁盘(PersistentDisk, PD)存放Volume的数据,它与emptyDir不同, PD上的内容会被永久存,当Pod被删除时, PD只是被卸载(Unmount),但不会被删除。需要注意是,你需要先创建一个永久磁盘(PD),才能使用gcePersistentDisk.
4. awsElasticBlockStore
与GCE类似,该类型的Volume使用亚马逊公有云提供的EBS Volume存储数据,需要先创建一个EBS Volume才能使用awsElasticBlockStore.
5. NFS
使用NFS网络文件系统提供的共享目录存储数据时,我们需要在系统中部署一个NFSServer,定义NES类型的Volume的示例如下yum -y install nfs-utils
1 | ... |
11、 Persistent Volume
Volume是定义在Pod上的,属于“计算资源”的一部分,而实际上, “网络存储”是相对独立于“计算资源”而存在的一种实体资源。比如在使用虚拟机的情况下,我们通常会先定义一个网络存储,然后从中划出一个“网盘”并挂接到虚拟机上
Persistent Volume(简称PV)和与之相关联的Persistent Volume Claim (简称PVC)也起到了类似的作用。PV可以理解成 Kubernetes集群中的某个网络存储中对应的一块存储,它与Volume很类似,但有以下区别。
| Persistent Volume与Volume的区别 |
|---|
| PV只能是网络存储,不属于任何Node,但可以在每个Node上访问。 |
| PV并不是定义在Pod上的,而是独立于Pod之外定义。 |
| PV目前支持的类型包括: gcePersistentDisk、 AWSElasticBlockStore, AzureFileAzureDisk, FC (Fibre Channel). Flocker, NFS, isCSI, RBD (Rados Block Device)CephFS. Cinder, GlusterFS. VsphereVolume. Quobyte Volumes, VMware Photon.PortworxVolumes, ScalelO Volumes和HostPath (仅供单机测试)。 |
1 | apiversion: v1 |
PV的accessModes属性, 目前有以下类型:
- ReadWriteOnce:读写权限、并且只能被单个Node挂载。
- ReadOnlyMany:只读权限、允许被多个Node挂载。
- ReadWriteMany:读写权限、允许被多个Node挂载。
如果某个Pod想申请某种类型的PV,则首先需要定义一个PersistentVolumeClaim (PVC)对象:
1 | kind: Persistentvolumeclaim |
引用PVC
1 | volumes: |
PV是有状态的对象,它有以下几种状态。 |
|---|
Available:空闲状态。 |
Bound:已经绑定到某个Pvc上。 |
Released:对应的PVC已经删除,但资源还没有被集群收回。 |
Failed: PV自动回收失败。 |
12、 Namespace (命名空间)
Namespace (命名空间)是Kubernetes系统中非常重要的概念, Namespace在很多情况下用于实现 **多租户的资源隔离**。Namespace通过将集群内部的资源对象“分配”到不同的Namespace 中,形成逻辑上分组的不同项目、小组或用户组,便于不同的分组在共享使用整个集群的资源的同时还能被分别管理。Kubernetes集群在启动后,会创建一个名为"default"的Namespace,通过kubectl可以查看到:
|不同的namespace之间互相隔离|
|–|–|
|查看所有命名空间|kubectl get ns|
|查看当前命名空间|kubectl config get-contexts|
|设置命名空间|kubectl config set-context 集群名 –namespace=命名空间|
kub-system 本身的各种 pod,是kubamd默认的空间。pod使用命名空间相互隔离
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible] |
命名空间基本命令
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible] |
命名空间切换
1 | ┌──[root@vms81.liruilongs.github.io]-[~/.kube] |
或者可以这样切换名称空间
1 | kubectl config set-context $(kubectl config current-context) --namespace=<namespace> |
创建pod时指定命名空间
1 | apiVersion: v1 |
当我们给每个租户创建一个Namespace来实现多租户的资源隔离时,还能结合Kubernetes"的资源配额管理,限定不同租户能占用的资源,例如CPU使用量、内存使用量等。
13、 Annotation (注解)
Annotation与Label类似,也使用key/value键值对的形式进行定义。
不同的是Label具有严格的命名规则,它定义的是Kubernetes对象的元数据(Metadata),并且用于Label Selector.
Annotation则是用户任意定义的“附加”信息,以便于外部工具进行查找, Kubernetes的模块自身会通过Annotation的方式标记资源对象的一些特殊信息。
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-pod-create] |
| 通常来说,用Annotation来记录的信息如下 |
|---|
| build信息、 release信息、Docker镜像信息等,例如时间戳、release id号、PR号、镜像hash值、 docker registry地址等。 |
| 日志库、监控库、分析库等资源库的地址信息。 |
| 程序调试工具信息,例如工具名称、版本号等。 |
| 团队的联系信息,例如电话号码、负责人名称、网址等。 |
关于 Kubernetes中一些基本概念和术语笔记
https://liruilongs.github.io/2021/11/23/K8s/API 学习/关于 Kubernetes中一些基本概念和术语笔记/
1.K8s 集群高可用master节点ETCD全部挂掉如何恢复?
2.K8s 集群高可用master节点故障如何恢复?
3.K8s 镜像缓存管理 kube-fledged 认知
4.K8s集群故障(The connection to the server <host>:<port> was refused - did you specify the right host or port)解决
5.关于 Kubernetes中Admission Controllers(准入控制器) 认知的一些笔记
6.K8s Pod 创建埋点处理(Mutating Admission Webhook)
7.关于AI(深度学习)相关项目 K8s 部署的一些思考
8.K8s Pod 安全认知:从openshift SCC 到 PSP 弃用以及现在的 PSA

