关于 Kubernetes中kube-controller-manager的一些笔记
我想变成一棵树. 开心时在秋天开花; 伤心时在春天落叶。 ——烽火戏诸侯《剑来》
写在前面
- 学习
K8s,遇到整理记忆 - 大部分都是书里或者官网的东西
- 博文内容为
kube-controller-manager的一些理论 - 涉及到常见控制器的一些说明
我想变成一棵树. 开心时在秋天开花; 伤心时在春天落叶。 ——烽火戏诸侯《剑来》
Kubernetes 控制器管理器是一个守护进程,内嵌随 Kubernetes 一起发布的核心控制回路。 控制回路是一个永不休止的循环(所以说K8S中的控制管理器是一个死循环),用于调节系统状态。
在 Kubernetes 中,每个控制器是一个控制回路,通过 API 服务器监视集群的共享状态, 并尝试进行更改以将当前状态转为期望状态。 目前,Kubernetes 自带的控制器例子包括副本控制器、节点控制器、命名空间控制器和服务账号控制器等。
Controller Manager 原理分析
Controller Manager作为集群内部的管理控制中心,当某个Node意外宕机时, Controller Manager会及时发现此故障并执行自动化修复流程,确保集群始终处于预期的工作状态。
Controller Manager内部包含Replication Controller, Node Controller, ResourceQuota Controller, Namespace Controller, ServiceAccount Controller, Token Controller,Service Controller及Endpoint Controller等多个Controller,每种Controller都负责一种具体的控制流程,而Controller Manager正是这些Controller的核心管理者。
副本控制器(Replication Controller)
其实对这个有些模糊,RC资源现在用的已经很少了,不知道这里只是指RC还是说RS,deploy都是由Replication Controller控制的
Replication Controller的核心作用是确保在任何时候集群中一个RC所关联的Pod副本数量保持预设值。
需要注意的一点是: 只有当Pod的重启策略是Always时(RestartPolicy=Always), Replication Controller才会管理该Pod的操作(例如创建、销毁、重启等)
RC 中的pod模板一旦创建完成,就和RC中的模板没有任何关系。 Pod可以通过修改标签来实现脱离RC的管控。可以用于 **将Pod从集群中迁移、数据修复等调试**。
对于被迁移的Pod副本, RC会自动创建一个新的,副本替换被迁移的副本。需要注意的是,删除一个RC不会影响它所创建的Pod,如果想删除一个RC所控制的Pod,则需要将该RC的副本数(Replicas)属性设置为0,这样所有的Pod副本都会被自动删除。
Replication Controller的职责:
Replication Controller的职责 |
|---|
| 确保当前集群中有且仅有N个Pod实例, N是RC中定义的Pod副本数量。 |
| 通过调整RC的spec.replicas属性值来实现系统扩容或者缩容。 |
| 通过改变RC中的Pod模板(主要是镜像版本)来实现系统的滚动升级。 |
使用场景
| 使用场景 |
|---|
| 重新调度(Rescheduling):副本控制器都能确保指定数量的副本存在于集群中 |
| 弹性伸缩(Scaling),手动或者通过自动扩容代理修改副本控制器的spec.replicas属性值,非常容易实现扩大或缩小副本的数量。 |
| 滚动更新(Rolling Updates),副本控制器被设计成通过逐个替换Pod的方式来辅助服务的滚动更新。即现在的deployment资源的作用,通过新旧两个RC 实现滚动更新 |
节点控制器(Node Controller)
kubelet进程在启动时通过API Server向master注册自身的节点信息,并定时向API Server汇报状态信息, API Server接收到这些信息后,将这些信息更新到etcd中, etcd中存储的节点信息包括节点健康状况、节点资源、节点名称、节点地址信息、操作系统版本、Docker版本、kubelet版本等。
节点健康状况包含“就绪” (True) “未就绪” (False)和“未知" (Unknown)三种。
Node Controller通过API Server实时获取Node的相关信息,实现管理和监控集群中的各个Node节点的相关控制功能, Node Controller的核心工作流程如图。
| Node Controller的核心工作流程如图 |
|---|
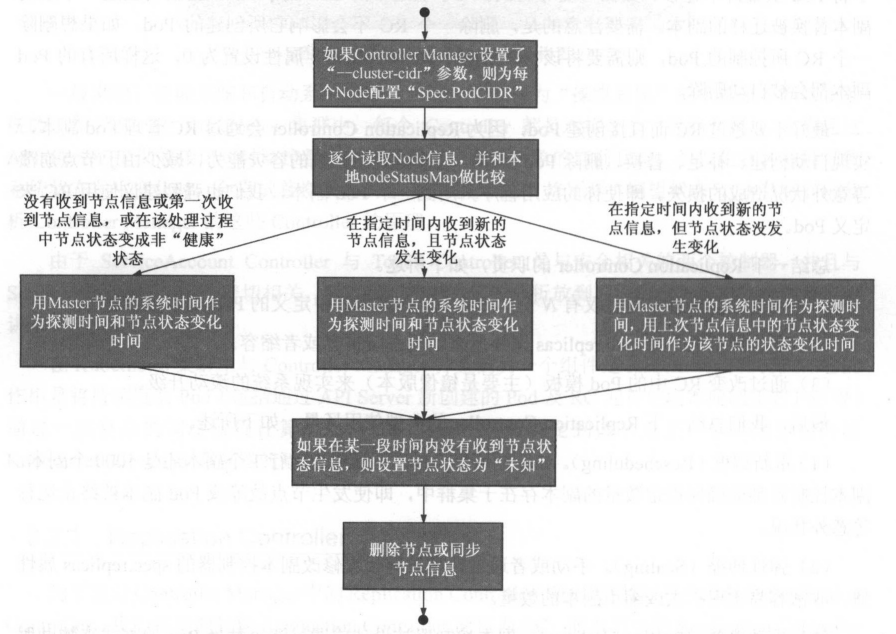 |
Controller Manager在启动时如果设置了-cluster-cidr参数,那么为每个没有设置Spec.PodCIDR的Node节点生成一个CIDR地址,并用该CIDR地址设置节点的Spec.PodCIDR属性,这样做的目的是防止不同节点的CIDR地址发生冲突。
逐个读取节点信息,多次尝试修改nodestatusMap中的节点状态信息,将该节点信息和Node Controller的nodeStatusMap中保存的节点信息做比较。
| 节点状态 |
|---|
如果判断出没有收到kubelet发送的节点信息、第1次收到节点kubelet发送的节点信息,或在该处理过程中节点状态变成非“健康”状态 |
则在nodeStatusMap中保存该节点的状态信息,并用Node Controller所在节点的系统时间作为探测时间和节点状态变化时间。 |
如果判断出在指定时间内收到新的节点信息,且节点状态发生变化 |
则在nodeStatusMap中保存该节点的状态信息,并用NodeController所在节点的系统时间作为探测时间和节点状态变化时间。 |
如果判断出在指定时间内收到新的节点信息,但节点状态没发生变化 |
则在nodeStatusMap中保存该节点的状态信息,并用Node Controller所在节点的系统时间作为探测时间,用上次节点信息中的节点状态变化时间作为该节点的状态变化时间。 |
如果判断出在某一段时间(gracePeriod)内没有收到节点状态信息 |
则设置节点状态为“未知” (Unknown),并且通过API Server保存节点状态。 |
如果节点状态变为非“就绪”状态 |
则将节点加入待删除队列,否则将节点从该队列中删除。 |
如果节点状态为非“就绪”状态,且系统指定了Cloud Provider,则Node Controller 调用Cloud Provider查看节点,若发现节点故障,则删除etcd中的节点信息,并删除和该节点相关的Pod等资源的信息。
资源控制器(ResourceQuota Controller)
Kubernetes提供了资源配额管理( ResourceQuotaController),确保了指定的资源对象在任何时候都不会超量占用系统物理资源,导致整个系统运行紊乱甚至意外宕机,对整个集群的平稳运行和稳定性有非常重要的作用。
Kubernetes支持资源配额管理。
| 配置级别 |
|---|
容器级别,可以对CPU和Memory进行限制。 |
Pod级别,可以对一个Pod内所有容器的可用资源进行限制。 |
Namespace级别,为Namespace (多租户)级别的资源限制,Pod数量;Replication Controller数量; Service数量;ResourceQuota数量;Secret 数量;可持有的PV (Persistent Volume)数量。 |
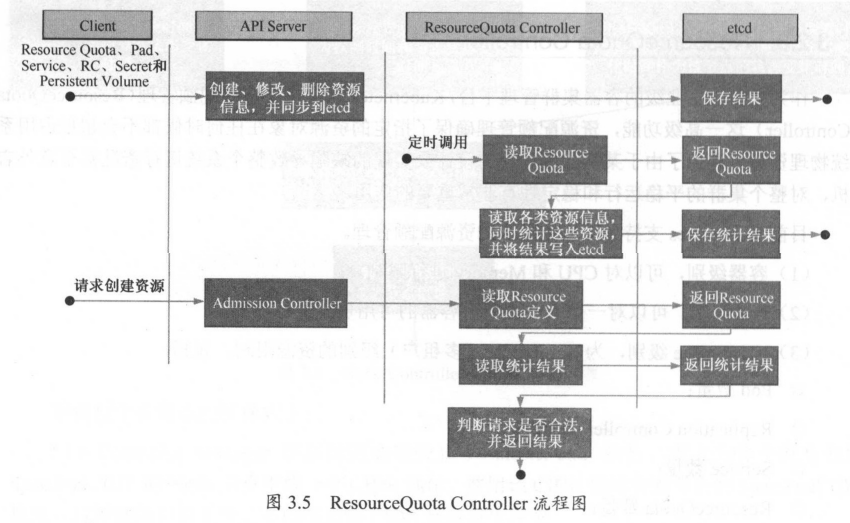
Kubernetes的配额管理是通过Admission Control (准入控制)来控制的, Admission Control当前提供了两种方式的配额约束,分别是LimitRanger与ResourceQuota。其中
LimitRanger作用于Pod和Container上,ResourceQuota则作用于Namespace上,限定一个Namespace里的各类资源的使用总额。
如果在
Pod定义中同时声明了LimitRanger,则用户通过API Server请求创建或修改资源时,Admission Control会计算当前配额的使用情况,如果不符合配额约束,则创建对象失败。
对于定义了
ResourceQuota的Namespace,ResourceQuota Controller组件则负责定期统计和生成该Namespace下的各类对象的资源使用总量,统计结果包括Pod, Service,RC、Secret和Persistent Volume等对象实例个数,以及该Namespace下所有Container实例所使用的资源量(目前包括CPU和内存),然后将这些统计结果写入etcd的resourceQuotaStatusStorage目录(resourceQuotas/status)中。
| ResourceQuota Controller 流程圖 |
|---|
 |
命名空间(Namespace Controller)
通过API Server可以创建新的Namespace并保存在etcd中, Namespace Controller定时通过API Server读取这些Namespace信息。
| 删除步骤 |
|---|
如果Namespace被API标识为优雅删除(通过设置删除期限,即DeletionTimestamp属性被设置),则将该NameSpace的状态设置成”Terminating“并保存到etcd中。同时Namespace Controller删除该Namespace下的ServiceAccount, RC, Pod.Secret, PersistentVolume, ListRange, ResourceQuota和Event等 **资源对象**。 |
当Namespace的状态被设置成”Terminating“后,由Admission Controller的NamespaceLifecycle插件来 阻止 为该Namespace创建新的资源。 |
在Namespace Controller删除完该Namespace中的所有资源对象后, Namespace Controller对该Namespace执行finalize操作,删除Namespace的spec.finalizers域中的信息 |
如果Namespace Controller观察到Namespace设置了删除期限,同时Namespace的spec.finalizers域值是空的,那么Namespace Controller将通过API Server删除该Namespace资源。 |
Service Controller(服务控制器)与Endpoint Controller
Service, Endpoints与Pod的关系
Endpoints表示一个Service对应的所有Pod副本的访问地址,而EndpointsController就是负责生成和维护所有Endpoints对象的控制器。
| – |
|---|
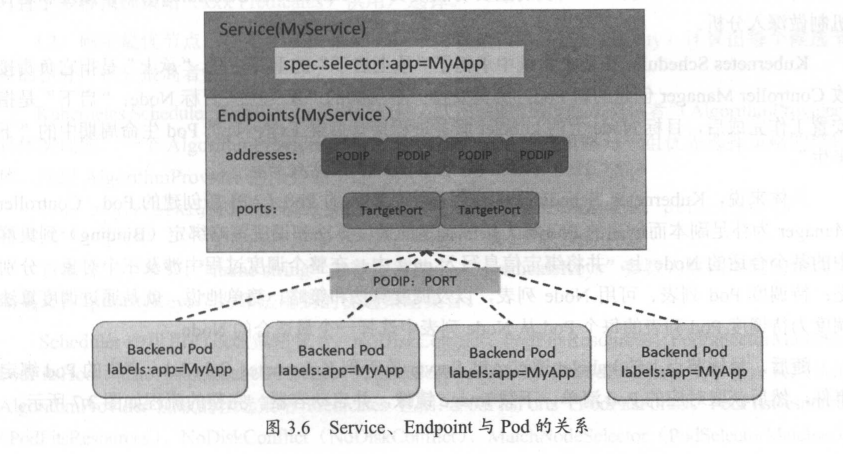 |
Endpoint Controller负责监听Service和对应的Pod副本的变化
Endpoint Controller监听 |
|---|
如果监测到Service被删除,则删除和该Service同名的Endpoints对象。 |
如果监测到新的Service被创建或者修改,则根据该Service信息获得相关的Pod列表,然后创建或者更新Service对应的Endpoints对象。 |
如果监测到Pod的事件,则更新它所对应的Service的Endpoints对象(增加、删除或者修改对应的Endpoint条目) |
Endpoints对象是在哪里被使用的呢?
每个
Node上的kube-proxy进程,kube-proxy进程获取每个Service的Endpoints,实现了Service的负载均衡功能。
Service Controller的作用,它其实是属于Kubernetes集群与外部的云平台之间的一个接口控制器。
Service Controller监听Service的变化,如果是一个LoadBalancer类型的Service (externalLoadBalancers-true),则Service Controller确保外部的云平台上该Service对应的LoadBalancer实例被相应地创建、删除及更新路由转发表(根据Endpoints的条目)。
yaml 资源文件
相关启动参数小伙伴可以移步官网查看: https://kubernetes.io/zh/docs/reference/command-line-tools-reference/kube-controller-manager/
1 | ┌──[root@vms81.liruilongs.github.io]-[~/ansible/k8s-svc-create] |
关于 Kubernetes中kube-controller-manager的一些笔记
https://liruilongs.github.io/2021/12/21/K8s/API 学习/关于 Kubernetes中kube-controller-manager的一些笔记/
1.K8s 集群高可用master节点ETCD全部挂掉如何恢复?
2.K8s 集群高可用master节点故障如何恢复?
3.K8s 镜像缓存管理 kube-fledged 认知
4.K8s集群故障(The connection to the server <host>:<port> was refused - did you specify the right host or port)解决
5.关于 Kubernetes中Admission Controllers(准入控制器) 认知的一些笔记
6.K8s Pod 创建埋点处理(Mutating Admission Webhook)
7.关于AI(深度学习)相关项目 K8s 部署的一些思考
8.K8s Pod 安全认知:从openshift SCC 到 PSP 弃用以及现在的 PSA

