┌──[root@vms81.liruilongs.github.io]-[~] └─$kubectl get nodes NAME STATUS ROLES AGE VERSION vms155.liruilongs.github.io NotReady <none> 76d v1.22.2 vms156.liruilongs.github.io Ready <none> 76d v1.22.2 vms81.liruilongs.github.io Ready control-plane,master 400d v1.22.2 vms82.liruilongs.github.io NotReady <none> 400d v1.22.2 vms83.liruilongs.github.io Ready <none> 400d v1.22.2 ┌──[root@vms81.liruilongs.github.io]-[~] └─$
我最开始以为 kubectl 的问题,排查了日志发现没有问题。
1 2 3 4 5 6 7 8
┌──[root@vms82.liruilongs.github.io]-[~] └─$systemctl status kubelet.service ● kubelet.service - kubelet: The Kubernetes Node Agent Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled) Drop-In: /usr/lib/systemd/system/kubelet.service.d └─10-kubeadm.conf Active: active (running) since 二 2023-01-17 20:53:02 CST; 1min 18s ago ....
然后在集群事件中,发现 Is the docker daemon running?, Error while dialing dial unix /run/containerd/containerd. sock: connect: connection refused": unavailable 类似的事件提示。
1 2 3 4 5 6 7 8 9 10 11 12 13
┌──[root@vms81.liruilongs.github.io]-[~] └─$kubectl get events | grep -i error 54m Warning Unhealthy pod/calico-node-nfkzd Readiness probe failed: calico/node is not ready: BIRD is not ready: Error querying BIRD: unable to connect to BIRDv4 socket: dial unix /var/run/bird/bird.ctl: connect: no such file or directory 54m Warning Unhealthy pod/calico-node-nfkzd Readiness probe failed: calico/node is not ready: BIRD is not ready: Error querying BIRD: unable to connect to BIRDv4 socket: dial unix /var/run/calico/bird.ctl: connect: connection refused 44m Warning FailedCreatePodSandBox pod/calico-node-vxpxt Failed to create pod sandbox: rpc error: code = Unknown desc = failed to start sandbox container for pod "calico-node-vxpxt": Error response from daemon: connection error: desc = "transport: Error while dialing dial unix /run/containerd/containerd.sock: connect: connection refused": unavailable 44m Warning FailedCreatePodSandBox pod/calico-node-vxpxt Failed to create pod sandbox: rpc error: code = Unknown desc = failed to start sandbox container for pod "calico-node-vxpxt": Error response from daemon: transport is closing: unavailable 44m Warning FailedCreatePodSandBox pod/kube-proxy-htg7t Failed to create pod sandbox: rpc error: code = Unknown desc = failed to start sandbox container for pod "kube-proxy-htg7t": Error response from daemon: connection error: desc = "transport: Error while dialing dial unix /run/containerd/containerd.sock: connect: connection refused": unavailable 44m Warning FailedCreatePodSandBox pod/kube-proxy-htg7t Failed to create pod sandbox: rpc error: code = Unknown desc = failed to start sandbox container for pod "kube-proxy-htg7t": Error response from daemon: transport is closing: unavailable 44m Warning FailedCreatePodSandBox pod/kube-proxy-htg7t Failed to create pod sandbox: rpc error: code = Unknown desc = failed to create a sandbox for pod "kube-proxy-htg7t": error during connect: Post "http://%2Fvar%2Frun%2Fdocker.sock/v1.41/containers/create?name=k8s_POD_kube-proxy-htg7t_kube-system_85fe510d-d713-4fe6-b852-dd1655d37fff_15": EOF 44m Warning FailedKillPod pod/skooner-5b65f884f8-9cs4k error killing pod: failed to "KillPodSandbox"for"eb888be0-5f30-4620-a4a2-111f14bb092d" with KillPodSandbo Error: "rpc error: code = Unknown desc = [networkPlugin cni failed to teardown pod \"skooner-5b65f884f8-9cs4k_kube-system\" network: error getting ClusterInformation: Get \"https://[10.96.0.1]:443/apis/crd.projectcalico.org/v1/clusterinformations/default\": dial tcp 10.96.0.1:443: connect: connection refused, Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?]" ┌──[root@vms81.liruilongs.github.io]-[~] └─$
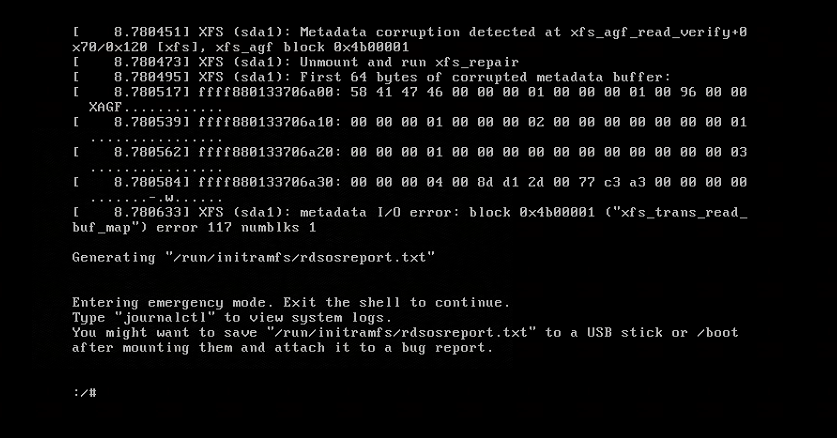
┌──[root@vms82.liruilongs.github.io]-[~] └─$systemctl restart containerd.service Job for containerd.service failed because the control process exited with error code. See "systemctl status containerd.service" and "journalctl -xe"for details.
查看 containerd 服务日志,这里先查看一下 error 的信息
1 2 3 4 5 6 7
┌──[root@vms82.liruilongs.github.io]-[~] └─$journalctl -u containerd | grep -i error -m 3 1月 17 20:41:56 vms82.liruilongs.github.io containerd[962]: time="2023-01-17T20:41:56.203387028+08:00" level=info msg="skip loading plugin \"io.containerd.snapshotter.v1.aufs\"..." error="aufs is not supported (modprobe aufs failed: exit status 1 \"modprobe: FATAL: Module aufs not found.\\n\"): skip plugin"type=io.containerd.snapshotter.v1 1月 17 20:41:56 vms82.liruilongs.github.io containerd[962]: time="2023-01-17T20:41:56.203699262+08:00" level=warning msg="failed to load plugin io.containerd.snapshotter.v1.devmapper" error="devmapper not configured" 1月 17 20:41:56 vms82.liruilongs.github.io containerd[962]: time="2023-01-17T20:41:56.204050775+08:00" level=info msg="skip loading plugin \"io.containerd.snapshotter.v1.zfs\"..." error="path /var/lib/containerd/io.containerd.snapshotter.v1.zfs must be a zfs filesystem to be used with the zfs snapshotter: skip plugin"type=io.containerd.snapshotter.v1 ┌──[root@vms82.liruilongs.github.io]-[~] └─$
aufs is not supported (modprobe aufs failed: exit status 1 \"modprobe: FATAL: Module aufs not found. path /var/lib/containerd/io.containerd.snapshotter.v1.zfs must be a zfs filesystem to be used with the zfs snapshotter: sk