Linux 常见性能分析方法论介绍(业务负载画像、下钻分析、USE方法论,检查清单)
不必太纠结于当下,也不必太忧虑未来,当你经历过一些事情的时候,眼前的风景已经和从前不一样了。——村上春树
写在前面
- 博文内容为
《BPF Performance Tools》读书笔记整理 - 内容涉及常用的性能调优方法论介绍:
- 业务负载画像
- 下钻分析
- USE方法论
- 检查清单
- 理解不足小伙伴帮忙指正
不必太纠结于当下,也不必太忧虑未来,当你经历过一些事情的时候,眼前的风景已经和从前不一样了。——村上春树
讲到性能分析,可以觉得有点高大上,实际上,性能分析在日常运维场景中很常见,系统故障往往可以是性能问题导致。
性能分析的目标是什么?
一般来说,性能分析的目标是
改进最终用户的体验降低运行成本
最好能将性能分析的目标进行量化定义;这种量化能够表明是否已经达到性能优化目标,还可以用来定义距离目标还有多少差距。可以测量的指标包括如下几项。
延迟:多久可以完成一次请求或操作,通常以毫秒为单位。速率:每秒操作或请求的速率吞吐量:通常指每秒传输的数据量,以比特(bit)或者字节(byte)为单位。利用率:以百分比形式表示的某资源在一段时间内的繁忙程度成本:开销/性能的比例。
最终用户眼中的性能,可以通过用户请求从发出到被响应之间所花费的时间来衡量,性能优化的目标就是缩短这个时间。这个等待时间被称为延迟
针对延迟的改进可以通过分析请求时间的组成,将其细分为各个组成部分,例如,
- CPU上运行代码的时间;
- 等待某个资源,比如磁盘IO、网络以及锁的时间,等待CPU 调度的时间等。
可以编写一个 BPF工具,直接跟踪应用的总体请求延迟以及各个部分的单独开销不过这样的工具会和具体应用相关,并且由于同时对多个事件进行跟踪会带来显著的运行开销。
在开展性能分析工作时请牢记上述目标。使用BPF工具,很容易出现这种情况:生成了大量数据,然后又花费了大量时间来理解这些数据,最后却发现该指标并不重要
首先应该明确工作目标是什么:我们是要降低请求延迟,还是降低运行成本?明确目标后,进一步的分析工作就有了上下文,不至于跑偏。
BPF性能分析工具,不只用于分析特定类型的问题。下表所示的是一个性能分析工作的列表,以及在每项工作中 BPF 性能分析工具可以发挥的作用。
| 性能分析活动 | BPF 性能分析工具 |
|---|---|
| 原型软件或硬件的性能特征分析 | 测量不同业务负载下的延迟直方图 |
| 在开发阶段、集成阶段之前的性能分析 | 解决性能瓶颈点,寻找一般的性能改进点 |
| 针对软件的某个版本,在发布前/后进行的非回归测试 | 从多个不同来源记录代码的使用和延迟数据,支持快速定位回归测试问题 |
| 基准测试,为软件发布的市场宣传工作提供数据支撑 | 研究性能问题,寻找机会改进基准测试性能 |
| 在目标环境下进行的概念验证(Proof-ofconcept)测试 | 生成延迟分布直方图,确保性能满足请求的服务等级协议(SLA) |
| 监控生产环境中运行的软件 | 编写可以 24x7运行的工具,提供新的、之前属于盲区的性能指标 |
| 故障排查时的性能分析 | 使用现成的工具或根据需要创建自定义的观测点来解决特定的性能问题 |
多重性能问题
同时发现多个性能问题,需要识别那个性能问题才是最重要的,通常是那些对延迟或者成本开销影响最大的性能问题。
开展那些工作对性能分析有帮助?(性能分析方法论)
如何处理性能分析工具提取的数据,需要机遇性能分析方法论,方法论是一个可以遵循的过程,指导从哪里开始,中间需要做些什么,从哪里结束。
业务负载画像
业务负载画像的目的是理解实际运行的业务负载。你不需要对最终的性能结果进行分析.
“消除不必要的工作”是笔者在性能优化结果中收益最显著的一种,通过研究业务负载的构成就可以找到这样的优化点。开展业务负载画像的推荐步骤如下:
- 负载是谁产生的(比如,进程ID、用户ID、进程名、IP地址)?
- 负载为什么会产生(代码路径、调用、火焰图)?
- 负载的组成是什么(IOPS、吞吐量、负载类型)?
- 负载怎样随着时间发生变化(比较每个周期的摘要信息)?
1 | vfsstat |
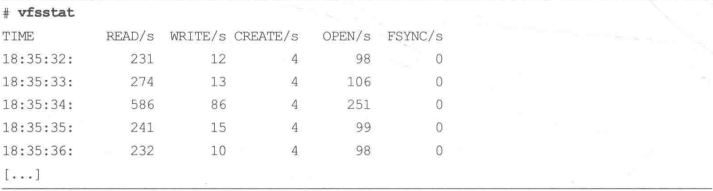
上面的输出显示了这虚拟文件系统 VFS 层面业务负载的细节,并且回答第三个问题,即负载类型和操作的速率,同时还通过周期性的输出信息回答了第四个问题
作为第一个问题的Demo,使用 bpftrace 运行一个单行的程序
1 | bpftrace -e 'kprobe:vfs_read { @[comm] == count(); }' |

输出显示了名称为“Web Content”的进程在上述测量期间执行了1725次 vfs read IO 操作。
第二个问题,可以通过火焰图来分析
下钻分析
下钻分析的工作过程是从一个指标开始,然后将这个指标拆分成多个组成部分,再将最大的组件进一步拆分为更小的组件,不断重复这个过程直到定位出一个或多个根因。
可以用一个类比来帮助解释这个过程。设想一下,如果你收到了一笔数额巨大的信用卡账单。为了分析它,需要登录到银行账户中调阅交易记录。在那里你发现了一笔线上书店的大额交易。然后你又登录到线上书店去看哪些书引发了这笔交易,结果有点意外:你发现不小心将此刻正在读的这本书购买了1000本(多谢!)。这就是下钻分析过程:先找到一个线索,然后拆分以寻找更深一步的线索,如此反复直到问题解决。下钻分析的推荐步骤如下:
- 从业务最高层级开始分析。
- 检查下一个层级的细节。
- 挑出最感兴趣的部分或者线索。
- 如果问题还没有解决,跳转至第2步。
下钻分析可能会涉及对工具进行定制,此时bpftrace 比 bcc 更加适合。有一种类型的下钻分析涉及将延迟分解为各个组成部分。想象一下下面的分析过程:
- 请求延迟 100ms 毫秒
- 有10ms在CPU上运行,90ms消耗在脱离CPU的等待过程。
- 在脱离CPU等待的部分中,有89ms阻塞于文件系统上。
- 文件系统的部分,有3ms阻塞于锁上,而86ms阻塞于存储设备上。
到此为止,你可能已经得出结论:存储设备是问题所在–这确实是一种答案。但是下钻分析可以使问题的上下文更清晰。设想另一种可能的分析过程:
- 一个应用花费了89ms被阻塞在文件系统上。
- 文件系统花费了78ms被阻塞在写操作上,11ms被阻塞在读操作上。
- 在文件系统写操作中,77ms被阻塞在时间戳的更新上。
此时,可以得出的结论是:文件系统访问时间戳是延迟的根源,它们可以被禁止(通过改变挂载选项)。这个分析结果要比“我们需要更快的磁盘”好得多。
USE方法论
通过 USE 方法论来对资源的使用情况进行分析
- 使用率
- 饱和度
- 错误
使用当前方法第一补是 绘制软件或者硬件资源图,然后一次对资源进行上述检查
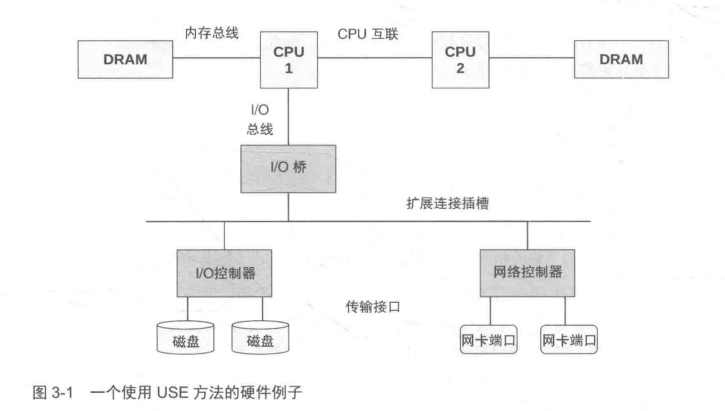
这个方法论的优势之一是,它以重要的问题作为开始,而非以某种指标形式的答案作为开始,反过来再去找出为什么它重要。这个方法论同时会帮助发现盲区:从你需要回答的问题开始,而不管是否已有工具能够方便测量。
检查清单法
性能分析检查清单可以列出一系列工具和指标,用于对照运行和检查。这些工具和指标可以聚焦于那些唾手可得的性能问题:列出十几个常见的问题,以及对应的分析方法,这样让每个人都能参照检查。这个方法论适用于指导公司各个层次的工程师实施操作,允许你将个人的技能应用于更广的范围内。
下面会给出两个清单,
一个使用了传统(非BPF)工具,比较适合于快速分析(开始的 60 秒);
另一个清单是适合及早使用的 BCC 工具列表。
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知 :)
《BPF Performance Tools》
© 2018-至今 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)
Linux 常见性能分析方法论介绍(业务负载画像、下钻分析、USE方法论,检查清单)
https://liruilongs.github.io/2024/03/30/rhca/RH442_BPF/BPF/Linux-性能分析方法论介绍-业务负载画像、下钻分析、USE方法论,检查清单/
1.Linux网络优化之从Linux内核epoll/io_uring 到Python(ASGI/WSGI)及Java Tomcat(BIO/NIO)网络IO模型认知
2.Linux网络调优之内核网络栈发包收包认知
3.Linux 性能调优之 OOM Killer 的认知与观测
4.为什么进程的物理内存占用(RSS)不停增长? 利用 BPF 跟踪、统计 Linux 缺页异常
5.如何使用 BPF 监控 Linux 用户态小内存分配:Linux 内存调优之 BPF 分析用户态小内存分配
6.Linux 内存调优之 BPF 分析用户态 mmap 大内存分配
7.如何使用 BPF 分析 Linux 内存泄漏,Linux 性能调优之 BPF 分析内核态、用户态内存泄漏
8.认识 Linux 内存构成:Linux 内存调优之页表、TLB、缺页异常、大页认知

