喜欢文字的人,大多敏感且心软,忽然不快乐忽然被回忆揪住心脏忽然沉默到泪流。或许是内心孤独的缘故,轻易便可从他人的故事里看到自己的影子所以,悲伤总要比别人多一半。
写在前面
博文内容涉及工具来自《BPF Performance Tools》 一书,
CPU性能指标涉及:
系统短期创建的线程进程跟踪
进程线程的CPU运行时长,脱离时长统计
线程的运行队列长度,等待延时时间,有多少线程在等待,多核队列是否均衡
线程运行调用栈和脱离调用栈跟踪
线程 软硬中断 CPU时间,LLC 三级缓存命中率分析
内核态系统调用跟踪分析
这里感谢译本的作者,抱着英文版的瞅了好久…,有条件小伙伴可以支持下
理解不足小伙伴帮忙指正 :),生活加油
喜欢文字的人,大多敏感且心软,忽然不快乐忽然被回忆揪住心脏忽然沉默到泪流。或许是内心孤独的缘故,轻易便可从他人的故事里看到自己的影子所以,悲伤总要比别人多一半。
实验环境,大部分是在 Rocky 上完成,Demo 需要 root 如果你用普通用户执行,会报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$hostnamectl Static hostname: vms99.liruilongs.github.io Icon name: computer-vm Chassis: vm Machine ID: ea70bf6266cb413c84266d4153276342 Boot ID: 0d01838b0095494c82d1befb174a317d Virtualization: vmware Operating System: Rocky Linux 8.9 (Green Obsidian) CPE OS Name: cpe:/o:rocky:rocky:8:GA Kernel: Linux 4.18.0-513.9.1.el8_9.x86_64 Architecture: x86-64 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$
传统的性能工具提供了对 CPU 各种用量的测量,比如CPU 的使用率(mpstat),平均负载(uptime),上下文切换(perf),软硬中断(proc/*)的CPU使用率,运行队列长度(mpstat)等,
BPF 跟踪工具可以提供更多细节信息,包括内核态和用户态的埋点跟踪,利用PMC来获取定时采样的CPU数据和CPU 内部数据
在使用 BPF 工具的时候需要考虑工具所带来的消耗问题,最糟糕的情况下,针对调度器的跟踪可能会消耗 10% 的系统性能。
通过 BPF 工具可以回答以下这些问题
系统短期创建了哪些新进程(线程)? execsnoop execsnoop(8) 可以列出新进程运行信息,是一个CPU调度监控工具,用于跟踪全系统中的新进程执行信息。利用这个工具可以找到 消耗大量CPU的短期进程,并且可以用来分析软件执行过程,包括启动脚本等。
execsnoop(8)直接跟踪 execve(2)系统调用(是最常用的exec(2)变体),可以直接打印 execve(2)的调用参数和返回值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ┌──[root@liruilongs.github.io]-[/usr/share/bcc/tools] └─$./execsnoop PCOMM PID PPID RET ARGS sshd 50066 1076 0 /usr/sbin/sshd -D -R unix_chkpwd 50068 50066 0 root unix_chkpwd 50069 50066 0 root bash 50071 50070 0 /bin/bash id 50072 50071 0 /usr/bin/id -un hostnamectl 50074 50073 0 /usr/bin/hostnamectl --transient 8 50075 1 0 /proc/self/fd/8 --deserialize 76 --log-level info --log-target journal-or-kmsg systemd-hostnam 50075 1 0 /usr/lib/systemd/systemd-hostnamed grepconf.sh 50077 50071 0 /usr/libexec/grepconf.sh -c grep 50078 50077 0 /usr/bin/grep -qsi ^COLOR.*none /etc/GREP_COLORS .................................
一般情况下 execsnoop(8)用来寻找高频出现、消耗资源的短期进程,比如那种频繁创建销毁的,或者是那种一直新建连接的。
列表解释:
PCOMM:进程名称PID:进程IDPPID:父进程IDRET:系统调用返回值,0表示成功ARGS:系统调用的参数
这里看一个特殊情况,用 py 的 multiprocessing 模块创建多个进程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 ┌──[root@vms99.liruilongs.github.io]-[~] └─$cat jc.py import multiprocessingimport timedef short_task (duration ): print (f"Task started, will run for {duration} seconds." ) time.sleep(duration) print (f"Task finished." ) if __name__ == "__main__" : processes = [] num_tasks = 5 task_duration = 2 for _ in range (num_tasks): p = multiprocessing.Process(target=short_task, args=(task_duration,)) processes.append(p) p.start() for p in processes: p.join() print ("All tasks completed." ) ┌──[root@vms99.liruilongs.github.io]-[~] └─$
运行命令测试
1 2 3 4 5 6 7 8 9 10 11 12 13 ┌──[root@vms99.liruilongs.github.io]-[~] └─$python jc.py Task started, will run for 2 seconds. Task started, will run for 2 seconds. Task started, will run for 2 seconds. Task started, will run for 2 seconds. Task started, will run for 2 seconds. Task finished. Task finished. Task finished. Task finished. Task finished. All tasks completed.
通过 execsnoop 来跟踪新的进程
1 2 3 4 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$./execsnoop PCOMM PID PPID RET ARGS python3 37950 2082 0 /usr/bin/python3 jc.py
会发现只有一个,这是为什么?这是因为默认情况下,multiprocessing 使用 os.fork() 来创建子进程,而没有执行 os.exec*() ,所以 execsnoop 无法捕捉到这些子进程的创建,前面我们有讲, execsnoop 主要跟踪 exec 以及对应的变体。
在执行的时候打印一下方法栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ........... File "/root/jc.py" , line 20, in <module> p.start() File "/usr/lib/python3.10/multiprocessing/process.py" , line 121, in start self._popen = self._Popen(self) File "/usr/lib/python3.10/multiprocessing/context.py" , line 224, in _Popen return _default_context.get_context().Process._Popen(process_obj) File "/usr/lib/python3.10/multiprocessing/context.py" , line 281, in _Popen return Popen(process_obj) File "/usr/lib/python3.10/multiprocessing/popen_fork.py" , line 19, in __init__ self._launch(process_obj) File "/usr/lib/python3.10/multiprocessing/popen_fork.py" , line 71, in _launch code = process_obj._bootstrap(parent_sentinel=child_r) File "/usr/lib/python3.10/multiprocessing/process.py" , line 314, in _bootstrap self.run() File "/usr/lib/python3.10/multiprocessing/process.py" , line 108, in run self._target(*self._args, **self._kwargs) File "/root/jc.py" , line 8, in short_task traceback.print_stack()
我们可以在源码的这个位置看到
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ┌──[root@liruilongs.github.io]-[~] └─$vim +71 /usr/lib/python3.10/multiprocessing/popen_fork.py .......... 62 def _launch(self, process_obj): 63 code = 1 64 parent_r, child_w = os.pipe() 65 child_r, parent_w = os.pipe() 66 self.pid = os.fork() 67 if self.pid == 0: 68 try: 69 os.close(parent_r) 70 os.close(parent_w) 71 code = process_obj._bootstrap(parent_sentinel=child_r) 72 finally: 73 os._exit(code) .......
在运维脚本中我们经常会用到 subprocess 模块来执行 命令行操作,也会遇到这种情况,默认情况下,subprocess 使用 os.fork() 和 os.exec*() 组合的方式来创建子进程,如果类似 multiprocessing ,只使用了 os.fork 但是没有使用 exec*(),就会无法被跟踪。
1 2 3 4 5 6 7 import subprocessprocess = subprocess.Popen(['python' , 'script.py' ], stdout=subprocess.PIPE) process = subprocess.Popen(['python' , 'script.py' ], stdout=subprocess.DEVNULL)
在编码中一般以线程为单位进行编码,线程也是 CPU 上下文切换的基本单位,那么线程的创建如何被跟踪?
thrcadsnoop thrcadsnoop(8),可以用来跟踪线程的创建,通过跟踪 pthread_create() 库调⽤来跟踪线程的创建
这里在看一个 Demo,通过 py 的 threading 模块创建多个线程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ┌──[root@vms99.liruilongs.github.io]-[~] └─$cat xc.py import threading import time def worker(): "" "线程执行的任务" "" time.sleep(3) print (f"Thread {threading.current_thread().name} is running" ) threads = [] for i in range(5): t = threading.Thread(target=worker, name=f"Thread-{i}" ) threads.append(t) t.start() for t in threads: t.join() print ("All threads have finished." )┌──[root@vms99.liruilongs.github.io]-[~] └─$
运行 Demo
1 2 3 4 5 6 7 8 ┌──[root@vms99.liruilongs.github.io]-[~] └─$python xc.py Thread Thread-0 is running Thread Thread-1 is running Thread Thread-3 is running Thread Thread-2 is running Thread Thread-4 is running All threads have finished.
通过输出可以看到线程的创建速度,以及创建线程的父ID,和线程的函数入口。
1 2 3 4 5 6 7 8 ┌──[root@vms99.liruilongs.github.io]-[~] └─$threadsnoop TIME(ms) PID COMM FUNC 0 12177 b'python3' b'[unknown]' 0 12177 b'python3' b'[unknown]' 0 12177 b'python3' b'[unknown]' 0 12177 b'python3' b'[unknown]' 0 12177 b'python3' b'[unknown]'
可以看大函数状态均为 [unknown],通常意味着 threadsnoop 无法获取当前线程正在执行的具体函数名。可能是由于缺乏调试信息或其他原因。
可以通过源码简单了解下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 ┌──[root@vms99.liruilongs.github.io]-[~] └─$cat /usr/share/bcc/tools/threadsnoop from __future__ import print_functionfrom bcc import BPFb = BPF(text=""" #include <linux/sched.h> struct data_t { u64 ts; u32 pid; u64 start; char comm[TASK_COMM_LEN]; }; BPF_PERF_OUTPUT(events); void do_entry(struct pt_regs *ctx) { struct data_t data = {}; data.ts = bpf_ktime_get_ns(); data.pid = bpf_get_current_pid_tgid() >> 32; data.start = PT_REGS_PARM3(ctx); bpf_get_current_comm(&data.comm, sizeof(data.comm)); events.perf_submit(ctx, &data, sizeof(data)); }; """ )try : b.attach_uprobe(name="pthread" , sym="pthread_create" , fn_name="do_entry" ) except Exception: b.attach_uprobe(name="c" , sym="pthread_create" , fn_name="do_entry" ) print ("%-10s %-7s %-16s %s" % ("TIME(ms)" , "PID" , "COMM" , "FUNC" ))start_ts = 0 def print_event (cpu, data, size ): global start_ts event = b["events" ].event(data) if start_ts == 0 : start_ts = event.ts func = b.sym(event.start, event.pid) if (func == "[unknown]" ): func = hex (event.start) print ("%-10d %-7d %-16s %s" % ((event.ts - start_ts) / 1000000 , event.pid, event.comm, func)) b["events" ].open_perf_buffer(print_event) while 1 : try : b.perf_buffer_poll() except KeyboardInterrupt: exit() ┌──[root@vms99.liruilongs.github.io]-[~] └─$
BPF 程序无法确定线程创建时调用的具体函数名
系统进程运行时长是多长?为什么退出了? exitsnoop exitsnoop(8)’是一个BCC 工具,用于跟踪进程的退出事件,打印出进程的总运行时长和退出原因。运行时长是指进程从创建到终止的时长,包括CPU运行时间和非运行时间(就绪和等待)。
使用的是sched:sched_process_exit内核跟踪点和它的参数信息,同时利用 bpf_get_current_task()以便从task 结构体中读取起始信息(这并不是一个稳定接口)。
这里我们使用上面的创建进程的 py 脚本来观察 exitsnoop
1 2 3 4 5 6 7 8 9 10 11 12 13 ┌──[root@vms99.liruilongs.github.io]-[~] └─$python jc.py Task started, will run for 2 seconds. Task started, will run for 2 seconds. Task started, will run for 2 seconds. Task started, will run for 2 seconds. Task started, will run for 2 seconds. Task finished. Task finished. Task finished. Task finished. Task finished. All tasks completed.
通过下面的输出可以看到,exitsnoop 和 execsnoop 虽然都可以用来调试短期进程,但是是的有区别的,exitsnoop 可以跟踪那些 没有调用 exec以及变体创建进程的进程,他同时会输出父进程和子进程的数据。
1 2 3 4 5 6 7 8 9 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$./exitsnoop PCOMM PID PPID TID AGE(s) EXIT_CODE python3 37904 37903 37904 2.00 0 python3 37908 37903 37908 2.00 0 python3 37907 37903 37907 2.00 0 python3 37906 37903 37906 2.00 0 python3 37905 37903 37905 2.01 0 python3 37903 2082 37903 2.04 0
输出信息中可以看到,最长时间的进程为父进程,上面的进程都为子进程。同时展示了线程ID,EXIT_CODE 列可以看到线程的退出状态码
线程每次唤醒时在CPU上花费多长时间? cpudist 通过 cpudist 可以展示每次线程唤醒之后在CPU上执行的时长分布的直方图。
需要说明 cpudist 在内部跟踪 CPU 调度器的上下文切换事件,在生产环境中如果频繁的上下文切换,那么这个工具的额外开销就很严重。
可以看到在 10 秒中 8192 -> 16383 us 为最多的时间区间,即线程在CPU上执行的时间相对较长,没有发生频繁的上下文切换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$cpudist 10 1 Tracing on-CPU time... Hit Ctrl-C to end. usecs : count distribution 0 -> 1 : 0 | | 2 -> 3 : 16 | | 4 -> 7 : 250 |*** | 8 -> 15 : 232 |*** | 16 -> 31 : 471 |******* | 32 -> 63 : 158 |** | 64 -> 127 : 70 |* | 128 -> 255 : 34 | | 256 -> 511 : 5 | | 512 -> 1023 : 0 | | 1024 -> 2047 : 12 | | 2048 -> 4095 : 45 | | 4096 -> 8191 : 160 |** | 8192 -> 16383 : 2621 |****************************************| 16384 -> 32767 : 602 |********* | 32768 -> 65535 : 288 |**** | 65536 -> 131071 : 27 | | 131072 -> 262143 : 2 | | ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$
使用 -m 参数可以按照毫秒数输出,这时可以看到 CPU 上线文切换非常快,每个线程运行时间为 0-1 毫秒,也就是 0-1000 微秒。实际上这是在一个空闲的机器的执行的。如果在一个生产系统,频繁的上线文切换,而且CPU 唤醒之后执行时间很少,就可能存在性能问题
1 2 3 4 5 6 7 8 9 10 11 12 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$cpudist -m Tracing on-CPU time... Hit Ctrl-C to end. ^C msecs : count distribution 0 -> 1 : 1019 |****************************************| 2 -> 3 : 0 | | 4 -> 7 : 0 | | 8 -> 15 : 1 | | ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$cpu
当前那些进程正在占用CPU,使用比例是多少? profile profile 是一个定时采样调用栈信息并汇报调用栈出现频率信息的一个工具,该工具的消耗基本可以忽略不计,而且采样频率可以随时调整。
默认情况下,该工具会以 49Hz 的频率同时采样所有的 CPU 内核态和用户态的调用栈信息。但是用户态的栈信息往往会获取不到
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$profile Sampling at 49 Hertz of all threads by user + kernel stack... Hit Ctrl-C to end. ^C _raw_spin_unlock_irqrestore _raw_spin_unlock_irqrestore prepare_to_swait_event rcu_gp_kthread kthread ret_from_fork - rcu_sched (14) 1 kmem_cache_alloc_node kmem_cache_alloc_node __alloc_skb __ip_append_data.isra.50 ip_append_data.part.51 ip_send_unicast_reply tcp_v4_send_reset tcp_v4_rcv ip_protocol_deliver_rcu ip_local_deliver_finish ip_local_deliver ip_rcv __netif_receive_skb_core process_backlog __napi_poll net_rx_action __softirqentry_text_start do_softirq_own_stack do_softirq.part.16 __local_bh_enable_ip ip_finish_output2 ip_output __ip_queue_xmit __tcp_transmit_skb tcp_connect tcp_v4_connect __inet_stream_connect inet_stream_connect __sys_connect __x64_sys_connect do_syscall_64 entry_SYSCALL_64_after_hwframe [unknown] - haproxy (1203) 1 show_vma_header_prefix show_vma_header_prefix show_map_vma show_map seq_read vfs_read ksys_read do_syscall_64 entry_SYSCALL_64_after_hwframe [unknown] [unknown] - awk (39726) 1 ............. ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$
通过输出我们可以看到,第一个采集的线程为 rcu_sched,PID 为 14, 采集可一次。与内核的 RCU 机制有关。
第二个调用栈数据为 haproxy 进程,pid 为 1203,通过内核态函数的调用可以看到主要进网络数据包的处理,以及TCP 连接的建立。
kmem_cache_alloc_node 表示分配内存。__ip_append_data 和 ip_send_unicast_reply 表示处理 IP 数据。tcp_v4_send_reset 和 tcp_v4_rcv 表示 TCP 协议的处理。__sys_connect 和 __x64_sys_connect 表示进行系统调用以建立连接。
实际中生产环境, 上面的输出会很多,所以一般情况会通过火焰图快速理解 prefile 的命令的输出。
火焰图 通过 -f 折叠输出,通过 -a 来标记 内核态和用户态函数。
1 2 ┌──[root@vms99.liruilongs.github.io]-[~] └─$profile -af 20 > profilelrl.log
需要使用 FlameGraph 项目来输出,所以这里我们克隆项目
1 2 3 4 5 6 7 8 9 10 11 ┌──[root@vms99.liruilongs.github.io]-[~] └─$git clone https://github.com/brendangregg/FlameGraph.git 正克隆到 'FlameGraph' ... remote: Enumerating objects: 1285, done . remote: Counting objects: 100% (707/707), done . remote: Compressing objects: 100% (146/146), done . remote: Total 1285 (delta 584), reused 575 (delta 561), pack-reused 578 接收对象中: 100% (1285/1285), 1.92 MiB | 174.00 KiB/s, 完成. 处理 delta 中: 100% (761/761), 完成. ┌──[root@vms99.liruilongs.github.io]-[~] └─$cd FlameGraph/
然后通过下面的命令生成对应的 火焰图 矢量图
1 2 3 4 ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$./flamegraph.pl --hash --bgcolors=grey < ../out.txt > out.svg Can't locate open.pm in @INC (you may need to install the open module) (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5) at ./flamegraph.pl line 97. BEGIN failed--compilation aborted at ./flamegraph.pl line 97.
可以看到报错了,这个错误消息表明在运行 ./flamegraph.pl 脚本时,Perl 解释器无法找到所需的 open.pm 模块。该模块可能没有正确安装或没有包含在 Perl 解释器的模块搜索路径中。
要解决这个问题,你可以尝试以下几个步骤:
检查模块安装:确保 open.pm 模块已经正确安装。你可以使用 CPAN 或其他 Perl 模块管理工具来安装该模块。
安装模块管理器
1 2 ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$yum install perl-CPAN -y
安装模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$cpan open Loading internal null logger. Install Log::Log4perl for logging messages CPAN.pm requires configuration, but most of it can be done automatically. If you answer 'no' below, you will enter an interactive dialog for each configuration option instead. Would you like to configure as much as possible automatically? [yes] yes CPAN: HTTP::Tiny loaded ok (v0.074) ............... http://www.cpan.org/modules/03modlist.data.gz Reading '/root/.cpan/sources/modules/03modlist.data.gz' DONE Writing /root/.cpan/Metadata Running install for module 'open' The most recent version "1.13" of the module "open" is part of the perl-5.38.2 distribution. To install that, you need to run force install open --or-- install P/PE/PEVANS/perl-5.38.2.tar.gz
安装完之后提示我们需要安装对应的 perl 版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$perl -v This is perl 5, version 26, subversion 3 (v5.26.3) built for x86_64-linux-thread-multi (with 58 registered patches, see perl -V for more detail) Copyright 1987-2018, Larry Wall Perl may be copied only under the terms of either the Artistic License or the GNU General Public License, which may be found in the Perl 5 source kit. Complete documentation for Perl, including FAQ lists, should be found on this system using "man perl" or "perldoc perl" . If you have access to the Internet, point your browser at http://www.perl.org/, the Perl Home Page. ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$yum -y install perl -y
升级 perl 版本之后,火焰图可以正常生成,通过帮助文档可以简单了解命令的使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ┌──[root@vms99.liruilongs.github.io]-[~] └─$./FlameGraph/flamegraph.pl --help USAGE: ./FlameGraph/flamegraph.pl [options] infile > outfile.svg --title TEXT --subtitle TEXT --width NUM --height NUM --minwidth NUM --fonttype FONT --fontsize NUM --countname TEXT --nametype TEXT --colors PALETTE --bgcolors COLOR --hash --random --cp --reverse --inverted --flamechart --negate --notes TEXT --help eg, ./FlameGraph/flamegraph.pl --title="Flame Graph: malloc()" trace.txt > graph.svg
输出我们上面的采集数据,启动一个 http 服务访问
1 2 3 4 5 6 7 8 9 ┌──[root@vms99.liruilongs.github.io]-[~] └─$./FlameGraph/flamegraph.pl < profilelrl.log > profilelrl.svg ┌──[root@vms99.liruilongs.github.io]-[~] └─$python -m http.server Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ... 192.168.26.1 - - [18/Oct/2024 05:15:37] "GET / HTTP/1.1" 200 - 192.168.26.1 - - [18/Oct/2024 05:15:37] code 404, message File not found 192.168.26.1 - - [18/Oct/2024 05:15:37] "GET /favicon.ico HTTP/1.1" 404 - 192.168.26.1 - - [18/Oct/2024 05:15:52] "GET /profilelrl.svg HTTP/1.1" 200 -
可以看到采集的应用程序调用栈很少,当前系统是一个空闲的系统,我们使用 stress 来做 CPU 负载模拟,所以看到的基本上是 stress 的调用栈
实际上生产场景的火焰图相对复杂
线程在运行队列中等待的时间有多长? runqlat CPU 调度的最小单位为线程,线程的运行队列长度可以反应CPU 是否处于饱和状态, runqlat 是基于 BCC 和 bpftrace 的 CPU 调度器延迟分析工具,CPU 调度器延迟通常被称为运行队列延迟,实际上不是简单的队列, runqlat 统计的是每个线程等待CPU的耗时。
这里我们通过 stress 来模拟CPU 的饱和状态。启动 100 个线程
1 2 3 4 5 6 ┌──[root@vms99.liruilongs.github.io]-[~] └─$stress --cpu 100 --timeout 100s stress: info: [38244] dispatching hogs: 100 cpu, 0 io, 0 vm, 0 hdd stress: info: [38244] successful run completed in 100s ┌──[root@vms99.liruilongs.github.io]-[~] └─$
下面的命令使用 runqlat 每隔 10 秒输出一次, 就输出一次的的直方图数据,
usecs:表示延迟的时间区间(以微秒为单位)。
count:表示在该时间区间内发生的事件数量。
distribution:通过星号 (*) 表示的分布图,用于可视化延迟的分布。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$./runqlat 10 1 Tracing run queue latency... Hit Ctrl-C to end. usecs : count distribution 0 -> 1 : 13 | | 2 -> 3 : 119 |** | 4 -> 7 : 355 |****** | 8 -> 15 : 183 |*** | 16 -> 31 : 144 |** | 32 -> 63 : 219 |*** | 64 -> 127 : 72 |* | 128 -> 255 : 21 | | 256 -> 511 : 22 | | 512 -> 1023 : 74 |* | 1024 -> 2047 : 143 |** | 2048 -> 4095 : 214 |*** | 4096 -> 8191 : 326 |***** | 8192 -> 16383 : 247 |**** | 16384 -> 32767 : 200 |*** | 32768 -> 65535 : 331 |***** | 65536 -> 131071 : 586 |********** | 131072 -> 262143 : 2295 |****************************************| 262144 -> 524287 : 1589 |*************************** | 524288 -> 1048575 : 554 |********* | 1048576 -> 2097151 : 31 | | 2097152 -> 4194303 : 1 | | ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$
可以看到,离群点为较高的延迟 131072 微秒及以上 占整个延迟区间的大部分,通过分布图也可以直观的感受。大部分线程处于等待状态,并且等待时间较长,可以确定当前CPU 呈现饱和状态。
runqlat(8)利用对 CPU 调度器的线程唤醒事件和线程上线文切换事件的跟踪来计算线程从唤醒到运行之前的时间间隔。
在比较繁忙的系统中,这类事件的发生频率可能很好,每秒超过10000次,所以在使用这个命令的时候需要多加注意。
也可以通过 sar(1) 来同时展示 CPU 利用率(-u) 和 运行队列性能指标(-q)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$sar -uq 1 Linux 4.18.0-513.9.1.el8_9.x86_64 (vms99.liruilongs.github.io) 2024年10月09日 _x86_64_ (6 CPU) 11时27分08秒 CPU %user %nice %system %iowait %steal %idle 11时27分09秒 all 96.13 0.00 3.87 0.00 0.00 0.00 11时27分08秒 runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked 11时27分09秒 100 592 15.81 14.33 11.57 0 11时27分09秒 CPU %user %nice %system %iowait %steal %idle 11时27分10秒 all 95.51 0.00 4.49 0.00 0.00 0.00 11时27分09秒 runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked 11时27分10秒 101 592 15.81 14.33 11.57 0
可以看到 用户态CPU 利用率为 趋于饱和,空闲时间为0,同时平均运行队列长度为 100左右,包括正在运行 + 等待的线程(与vmstat的r列相同), 1,5,15 分钟的负载为 15 左右,但是通过下面的输出可以看到当前我们只有6个逻辑核。
1 2 3 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$lscpu | grep CPU: CPU: 6
一般情况下,平均负载ldavg-1 ldavg-5 ldavg-15远远超过 CPU 逻辑核数的的时候,认为系统负载非常高,CPU 趋于饱和状态 ,通过 runq-sz > CUP数量 我们可以推断出 平局负载高的原因之一是因为 存在大量的线程在等待CPU调度,堆积在运行队列
实际上对于运行队列的长度我们也可以通过专门的 BPF 工具来采集
运行队列最长的时候有多少线程在等待执行? runqlen runqlen 是一个基于 BCC 和 bpftrace 的工具,用于采样 CPU运行队列的长度信息,统计有多少线程正在等待运行,同样可以以直方图的形式展现。
下面的输出为一台空闲的机器的 运行队列长度采集输出。可以看到,大部分时间的运行队列的长度都为0,即线程不需要等待可以立即执行。
1 2 3 4 5 6 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$./runqlen 10 1 Sampling run queue length... Hit Ctrl-C to end. runqlen : count distribution 0 : 5123 |****************************************|
通过 stress 来模拟 CPU 饱和
1 2 3 ┌──[root@vms99.liruilongs.github.io]-[~] └─$stress --cpu 100 --timeout 100s stress: info: [38556] dispatching hogs: 100 cpu, 0 io, 0 vm, 0 hdd
同样的命令再次执行,可以很明显的看到变化,队列长度集中在 10 到 25 之间,即大部分的CPU任务存在积压,线程需要等待才能执行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$./runqlen 10 1 Sampling run queue length... Hit Ctrl-C to end. runqlen : count distribution 0 : 367 |******************************* | 1 : 73 |****** | 2 : 39 |*** | 3 : 53 |**** | 4 : 57 |**** | 5 : 45 |*** | 6 : 83 |******* | 7 : 90 |******* | 8 : 97 |******** | 9 : 84 |******* | 10 : 118 |********** | 11 : 135 |*********** | 12 : 189 |**************** | 13 : 110 |********* | 14 : 166 |************** | 15 : 170 |************** | 16 : 318 |*************************** | 17 : 297 |************************* | 18 : 459 |****************************************| 19 : 232 |******************** | 20 : 308 |************************** | 21 : 358 |******************************* | 22 : 213 |****************** | 23 : 137 |*********** | 24 : 141 |************ | 25 : 143 |************ | 26 : 93 |******** | 27 : 42 |*** | 28 : 63 |***** | 29 : 58 |***** | 30 : 33 |** | 31 : 29 |** | 32 : 8 | | 33 : 33 |** | 34 : 10 | | 35 : 13 |* | 36 : 0 | | 37 : 0 | | 38 : 3 | | ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$
原书作者把运行队列被定义为二级指标,而且运行时间延迟被定义为一级指标,因为运行队列延迟会直接的按比例影响系统性能,而运行队列长度则不一样。
runqlen 可以进一步定性 runqlat 发现的问题,同时,runqlen 的采样频率为 99HZ,而 runqlat 需要跟踪 CPU 调度器,后者比前者有更多的性能消耗,一般情况下,会通过 runqlen 来发现问题,通过runqlat 的量化延迟,确定问题。
当进程进行单CPU亲和性配置的时候,一个进程的多个线程始终中一个CPU运行,这个时候,如果队列长度为3,即可确定该进程,有一个线程中运行,3线程位于队列中。
runqlat 和 runqlen 可以分析当前系统CPU使用异常是否存在由CPU调度延迟影响的,那么如果确定之后,如何定位到具体的线程,或者说应用程序?
runqslower runqslower 可以列出运行队列中等待延迟超过阈值的线程名字,同时输出受延迟影响的进程名字和对应的延迟时长
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$./runqslower Tracing run queue latency higher than 10000 us TIME COMM TID LAT(us) 12:11:12 b'stress' 39402 13089 12:11:12 b'stress' 39401 14679 12:11:12 b'stress' 39397 23660 12:11:12 b'stress' 39395 17852 12:11:12 b'kworker/u256:28' 573 22854 12:11:12 b'stress' 39398 34532 12:11:12 b'stress' 39399 52749 12:11:12 b'stress' 39400 107725 12:11:12 b'runqslower' 39303 76346 12:11:12 b'kworker/u256:28' 573 11797 12:11:12 b'stress' 39408 10779 12:11:12 b'stress' 39405 134470 12:11:12 b'runqslower' 39303 10063 12:11:12 b'stress' 39410 19963 12:11:12 b'stress' 39407 150640 12:11:12 b'runqslower' 39303 11418 12:11:12 b'stress' 39370 13291 12:11:12 b'stress' 39403 132886 12:11:12 b'runqslower' 39303 33169 12:11:12 b'stress' 39390 121633
上面的输出为超过默认阈值 10000 us 毫秒的的运行队列发生的次数,可以看到大多为上面的测试工具 stress 的线程。LAT(us)为线程在运行队列中的等待延迟,单位是微秒。
不同 CPU之间的运行队列是否均衡? runqlen 当其他运行队列中有需要运行的程序时,我们希望知道哪些CPU仍然处于空闲状态? 即对于每个进程,每个 CPU 的权重是否一致,是否存在不均衡的情况。通过 runqlen 的 -C 选项可以为每个CPU输出一个直方图。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$./runqlen -C Sampling run queue length... Hit Ctrl-C to end. ^C cpu = 1 runqlen : count distribution 0 : 0 | | 1 : 0 | | 2 : 0 | | 3 : 0 | | 4 : 0 | | 5 : 0 | | 6 : 0 | | 7 : 92 |*********************** | 8 : 0 | | 9 : 65 |**************** | 10 : 0 | | 11 : 77 |******************* | 12 : 0 | | 13 : 0 | | 14 : 157 |****************************************| cpu = 0 runqlen : count distribution 0 : 0 | | 1 : 0 | | 2 : 0 | | 3 : 0 | | 4 : 0 | | 5 : 0 | | 6 : 0 | | 7 : 0 | | 8 : 0 | | 9 : 0 | | 10 : 0 | | 11 : 0 | | 12 : 0 | | 13 : 0 | | 14 : 0 | | 15 : 0 | | 16 : 0 | | 17 : 0 | | 18 : 0 | | 19 : 333 |****************************************| 20 : 0 | | 21 : 0 | | 22 : 0 | | 23 : 0 | | 24 : 132 |*************** | ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$
可以很直观的看的 每个 CPU 上的线程队列长度,CPU 0 和 CPU 1 的运行队列长度分布存在明显的差异,这表明两个 CPU 的运行队列并不均衡,CPU0 的负载要高于 CPU1.可能是CPU 亲和性配置,或者编码中绑定了CPU
cpuunclaimed cpu_unclaimed 工具用于采样 CPU 运行队列的长度,并关注在某个 CPU 上有排队线程的情况下有多少其他 CPU 处于空闲状态。这个工具可以帮助识别 CPU 资源分配的不均衡问题,
这个命令在我的实验环境中会报错,时间关系我也没有研究,感兴趣小伙伴可以留言讨论,
下面为一个Demo数据,表示在 12:34:56 时,CPU 0 上有 10 个线程排队,而有 3 个 CPU 处于空闲状态。
1 2 3 4 5 TIME CPU QUEUE_LENGTH IDLE_CPUS 12:34:56 0 10 3 12:34:57 1 5 2 12:34:58 2 0 4 ...
为什么某个线程会主动脱离CPU?脱离时间有多长? offcputime offcputime(8) 用于统计线程阻塞和脱离CPU 运行的时间,同时会输出调用栈信息,
输出顺序依次为 内核态函数,用户态件函数,之后是进程名字,ID 以及调用栈出现的全部时间,也就是脱离时间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$offcputime 1 Tracing off-CPU time (us) of all threads by user + kernel stack for 1 secs. 。。。。。。。。。。。。。。。。。。。。。。。。。。 finish_task_switch __sched_text_start schedule schedule_hrtimeout_range_clock do_select core_sys_select kern_select __x64_sys_select do_syscall_64 entry_SYSCALL_64_after_hwframe __select - httpd (38029) 921073 finish_task_switch __sched_text_start schedule schedule_hrtimeout_range_clock do_select core_sys_select kern_select __x64_sys_select do_syscall_64 entry_SYSCALL_64_after_hwframe __select - tuned (1713) 947681 。。。。。。。。 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$
以上面的 httpd 为例,httpd 服务被阻塞,进程号为38029,脱离时长为 38029 微秒。
可以看到只有内核态函数,没有用户态函数,栈顶函数为 __select,用于在内核中处理文件描述符的状态检查。一旦某个文件描述符变为可用,或超时发生,__select 将返回,表明可以开始进行相应的 I/O 操作。即可以立即为当前进行脱离CPU的原因为 IO 阻塞。
offcputime 同时也可以用来分析并发的场景,比如长时间的锁等待之类,通过对函数的调用栈进行分析。
看一个 lock 的 Demo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ┌──[root@vms99.liruilongs.github.io]-[~] └─$cat lock_demo.py import threading import time lock = threading.Lock() def worker(id): print (f"Worker {id} started" ) with lock: print (f"Worker {id} acquired lock" ) time.sleep(2) print (f"Worker {id} released lock" ) threads = [] for i in range(5): t = threading.Thread(target=worker, args=(i,)) threads.append(t) t.start() for t in threads: t.join() print ("All workers finished" )
一个基本的线程安全Demo,执行分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ┌──[root@vms99.liruilongs.github.io]-[~] └─$python lock_demo.py Worker 0 started Worker 0 acquired lock Worker 1 started Worker 2 started Worker 3 started Worker 4 started Worker 0 released lock Worker 1 acquired lock Worker 1 released lock Worker 2 acquired lock Worker 2 released lock Worker 3 acquired lock Worker 3 released lock Worker 4 acquired lock Worker 4 released lock All workers finished
threadsnoop 观察线程创建情况
1 2 3 4 5 6 7 8 ┌──[root@vms99.liruilongs.github.io]-[~] └─$threadsnoop TIME(ms) PID COMM FUNC 0 51671 b'python3' b'[unknown]' 0 51671 b'python3' b'[unknown]' 0 51671 b'python3' b'[unknown]' 0 51671 b'python3' b'[unknown]' 0 51671 b'python3' b'[unknown]'
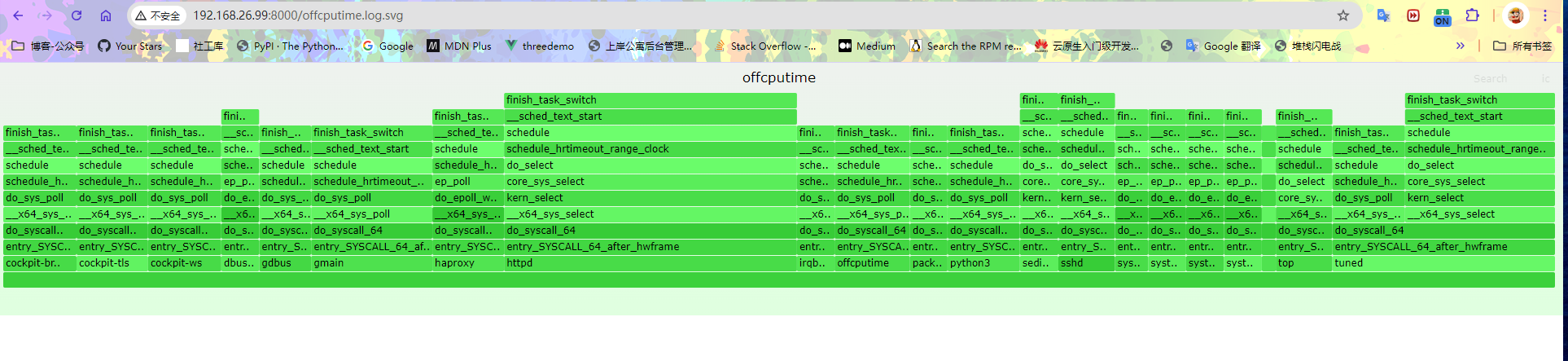
offcputime 观察脱离情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$offcputime -p `pgrep -f lock_demo.py` Tracing off-CPU time (us) of PID 51397 by user + kernel stack... Hit Ctrl-C to end. ^C ....................... finish_task_switch __sched_text_start schedule futex_wait_queue_me futex_wait do_futex __x64_sys_futex do_syscall_64 entry_SYSCALL_64_after_hwframe [unknown] - python3 (51402) 157 finish_task_switch __sched_text_start schedule futex_wait_queue_me futex_wait do_futex __x64_sys_futex do_syscall_64 entry_SYSCALL_64_after_hwframe [unknown] - python3 (51400) 213 finish_task_switch __sched_text_start schedule futex_wait_queue_me futex_wait do_futex __x64_sys_futex do_syscall_64 entry_SYSCALL_64_after_hwframe [unknown] - python3 (51397) 267 finish_task_switch __sched_text_start schedule do_nanosleep hrtimer_nanosleep common_nsleep_timens __x64_sys_clock_nanosleep do_syscall_64 entry_SYSCALL_64_after_hwframe [unknown] [unknown] - python3 (51400) 2002609 finish_task_switch __sched_text_start schedule do_nanosleep hrtimer_nanosleep common_nsleep_timens __x64_sys_clock_nanosleep do_syscall_64 entry_SYSCALL_64_after_hwframe [unknown] [unknown] - python3 (51402) 2003178 .................. ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$
简单分析调用栈中的函数:
futex_wait_queue_me 和 futex_wait:这些函数表明线程正在等待一个 futex(快速用户空间锁),通常是由于线程在等待某个锁或条件变量。
do_futex 和 __x64_sys_futex:这些函数表示进行系统调用以处理 futex。
do_nanosleep 和 hrtimer_nanosleep:这些函数表明线程正在进行睡眠操作(例如,使用 time.sleep()),使其在指定的时间内脱离 CPU。
unknown 这是一个用户态方法没有捕获到函数名字
多个线程在竞争同一个锁,导致它们在 futex 等待队列中排队。这是并发编程中常见的问题,尤其是在使用锁或条件变量时。
脱离CPU 火焰图 和火焰图一样,实际上面的输出会很多,通过脱离火焰图可以更方便的查看。
1 2 ┌──[root@vms99.liruilongs.github.io]-[~] └─$./FlameGraph/flamegraph.pl --bgcolors=green --colors=green --title='offcputime' --height=20 --width=1926 < offcputime.log > offcputime.log.svg
当前系统的所以脱离CPU数据
下转到某个线程查看
哪些软中断和硬中断占用了CPU 时间? 长时间的软硬中断通过会到来性能问题
softirqs softirqs(8) 用于显示系统中软中断消耗的CPU 时间,软中断事件的计数记录在 /proc/softirqs 中,全系统的软中断可以通过 mpstat(1) 中的 %soft 列显示
BCC版本的 softirqs 可以计数,同时可以输出每个 IRQ 的处理时间。
1 2 3 4 5 6 7 8 9 10 11 12 13 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$softirqs 10 1 Tracing soft irq event time... Hit Ctrl-C to end. SOFTIRQ TOTAL_usecs net_tx 6 block 21 net_rx 203 sched 3456timer 7674 rcu 72515 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$
列明解释:
SOFTIRQ:软中断的类型。TOTAL_usecs:每种软中断类型在采样期间消耗的总微秒数。
上面的软中断类型:
net_tx:网络数据包发送软中断,消耗了6微秒。block:块设备I/O软中断,消耗了21微秒。net_rx:网络数据包接收软中断,消耗了203微秒。sched:调度软中断,消耗了3456微秒。例如进程切换timer:定时器软中断,消耗了7674微秒。例如周期性任务rcu:RCU(Read-Copy-Update)软中断,消耗了72515微秒。主要用于并发数据结构的更新。
-d 将 IRQ 时间以直方图显示,可以直观的识别中断处理中某些耗时很长的情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$softirqs -d 10 1 Tracing soft irq event time... Hit Ctrl-C to end. softirq = sched usecs : count distribution 0 -> 1 : 34 |*** | 2 -> 3 : 318 |******************************** | 4 -> 7 : 394 |****************************************| 8 -> 15 : 31 |*** | 16 -> 31 : 10 |* | 32 -> 63 : 8 | | 64 -> 127 : 0 | | 128 -> 255 : 1 | | softirq = timer usecs : count distribution 0 -> 1 : 2 | | 2 -> 3 : 41 |***** | 4 -> 7 : 228 |******************************** | 8 -> 15 : 280 |****************************************| 16 -> 31 : 26 |*** | 32 -> 63 : 36 |***** | 64 -> 127 : 15 |** | 128 -> 255 : 2 | | softirq = net_rx usecs : count distribution 0 -> 1 : 20 |****************************************| 2 -> 3 : 4 |******** | 4 -> 7 : 10 |******************** | 8 -> 15 : 17 |********************************** | 16 -> 31 : 8 |**************** | 32 -> 63 : 5 |********** | 64 -> 127 : 4 |******** | 128 -> 255 : 1 |** | softirq = rcu usecs : count distribution 0 -> 1 : 377 |****************************************| 2 -> 3 : 37 |*** | 4 -> 7 : 65 |****** | 8 -> 15 : 30 |*** | 16 -> 31 : 59 |****** | 32 -> 63 : 7 | | 64 -> 127 : 2 | | 128 -> 255 : 1 | | softirq = tasklet usecs : count distribution 0 -> 1 : 0 | | 2 -> 3 : 0 | | 4 -> 7 : 0 | | 8 -> 15 : 0 | | 16 -> 31 : 0 | | 32 -> 63 : 1 |****************************************| softirq = block usecs : count distribution 0 -> 1 : 0 | | 2 -> 3 : 0 | | 4 -> 7 : 0 | | 8 -> 15 : 0 | | 16 -> 31 : 4 |****************************************| softirq = net_tx usecs : count distribution 0 -> 1 : 0 | | 2 -> 3 : 2 |****************************************| 4 -> 7 : 1 |******************** | ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$
可以看到大部分软中断处理时间都在 0 到 15 微秒之间,这表明系统对于大多数常见事件(如网络接收、定时器等)的响应是高效的。
一些软中断的处理时间较长(如 RCU 和定时器),可能需要进一步调查以优化性能。
tasklet 和 block 软中断的触发频率较低,可能表明这些功能在当前负载下使用不多。
hardirqs hardirqs 用来显示 硬中断的时间,和软中断的使用方法一样,
1 2 3 4 5 6 7 8 9 10 11 12 13 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$hardirqs 10 1 Tracing hard irq event time... Hit Ctrl-C to end. HARDIRQ TOTAL_usecs ens160-rxtx-0 5 ens160-rxtx-2 6 nvme0q3 22 nvme0q4 22 nvme0q2 23 ahci[0000:02:03.0] 39 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$
ens160-rxtx*: 网络相关的收发操作,中断时间很少nvme0q* : 与 NVMe 存储设备的队列相关的硬中断ahci[0000:02:03.0]: 与 AHCI 控制器相关的硬中断,处理时间为 39 微秒。这个时间相对较长,可能指示在处理 SATA 设备数据时存在一些延迟
也可以以直方图的形式输出 IRQ 时间信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$hardirqs -Td 10 1 Tracing hard irq event time... Hit Ctrl-C to end. 06:37:27 hardirq = nvme0q5 usecs : count distribution 0 -> 1 : 0 | | 2 -> 3 : 0 | | 4 -> 7 : 0 | | 8 -> 15 : 1 |************* | 16 -> 31 : 3 |****************************************| 32 -> 63 : 1 |************* | hardirq = ens160-rxtx-0 usecs : count distribution 0 -> 1 : 26 |****************************** | 2 -> 3 : 26 |****************************** | 4 -> 7 : 34 |****************************************| 8 -> 15 : 8 |********* | hardirq = ens160-rxtx-1 usecs : count distribution 0 -> 1 : 9 |*************************** | 2 -> 3 : 13 |****************************************| 4 -> 7 : 6 |****************** | .................
为什么CPU系统时间很高? 当CPU 存在很高的 内核态占用的时候,我们需要分析具体的原因
syscount syscount 用来统计系统中的系统调用数量,用于解决内核态使用率高是不是由于系统调用导致的?具体是哪些系统调用?
每 10 秒的系统调用输出,可以看到最频繁的是 select,用于 I/O 处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$syscount -i 10 Tracing syscalls, printing top 10... Ctrl+C to quit. [12:28:20] SYSCALL COUNT select 729 semop 188 bpf 55 epoll_wait 52 setsockopt 51 connect 50 close 29 socket 26 fcntl 25 read 15.............. Detaching... ┌──[root@vms99.liruilongs.github.io]-[/usr/share/bcc/tools] └─$
如果我们确定了某个系统调用很频繁,需要进一步分析,可以使用 argdist 来通过内核跟踪点或者内核函数来统计调用的参数和返回值
argdist 以上文的 read 内核函数为例,通过 tplist 方法获取参数信息
1 2 3 4 5 6 7 ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$tplist -v syscalls:sys_enter_read syscalls:sys_enter_read int __syscall_nr; unsigned int fd; char * buf; size_t count;
count 为调用的读缓存大小,然后使用 argdist 来输出直方图信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$argdist -H 't:syscalls:sys_enter_read():int:args->count' .............. [06:20:16] args->count : count distribution 0 -> 1 : 0 | | 2 -> 3 : 0 | | 4 -> 7 : 0 | | 8 -> 15 : 0 | | 16 -> 31 : 0 | | 32 -> 63 : 0 | | 64 -> 127 : 0 | | 128 -> 255 : 0 | | 256 -> 511 : 0 | | 512 -> 1023 : 0 | | 1024 -> 2047 : 0 | | 2048 -> 4095 : 0 | | 4096 -> 8191 : 0 | | 8192 -> 16383 : 0 | | 16384 -> 32767 : 1 |****************************************| ^C┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$
可以看到,当前的read 调用缓存集中在 16384 -> 32767 字节
然后将这个值与系统调用的返回值进行比对,也就是实际读取的字节数量,进一步分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$tplist -v syscalls:sys_exit_read syscalls:sys_exit_read int __syscall_nr; long ret; ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$ ┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$argdist -H 't:syscalls:sys_exit_read():int:args->ret' 。。。。。。。。 [06:22:02] args->ret : count distribution 0 -> 1 : 0 | | 2 -> 3 : 0 | | 4 -> 7 : 0 | | 8 -> 15 : 17 |****************************************| 16 -> 31 : 0 | | 32 -> 63 : 1 |** | 64 -> 127 : 0 | | 128 -> 255 : 1 |** | 256 -> 511 : 0 | | 512 -> 1023 : 1 |** | ^C┌──[root@vms99.liruilongs.github.io]-[~/FlameGraph] └─$
对于系统调用的统计,也可以使用 -P 选项指定跟踪某个进程,这里的1 为 systemd,这样会以进程的维度来统计系统调用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ┌──[root@vms99.liruilongs.github.io]-[~] └─$syscount -Pi 1 Tracing syscalls, printing top 10... Ctrl+C to quit. [06:14:09] PID COMM COUNT 12442 cockpit-bridge 11603 51948 top 2027 955 tuned 47 55669 syscount 23 2681 httpd 20 1126 haproxy 19 2680 httpd 18 12122 sshd 9 2679 httpd 9 51745 sshd 9 .............
可以看到调用最多的为 cockpit-bridge,是一个自带的系统工具,用于远程管理。
应用程序处理每个请求时的LLC的命中率是多少? 通过对缓存命中率的分析,可以优化编码,提高缓存利用率,llcstat 为共享缓存的命中率分析。
llcstat llcstat 用于利用性能监控计数器(PMC)来按进程输出最后一级缓存的命中率,LLC ,一般指多核共享缓存。
在虚拟机中执行会报错,没有PMC 信息,下面为文档的Demo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 Running for 20 seconds or hit Ctrl-C to end. PID NAME CPU REFERENCE MISS HIT% 0 swapper/15 15 3515000 640000 81.79% 238 migration/38 38 5000 0 100.00% 4512 ntpd 11 5000 0 100.00% 150867 ipmitool 3 25000 5000 80.00% 150895 lscpu 17 280000 25000 91.07% 151807 ipmitool 15 15000 5000 66.67% 150757 awk 2 15000 5000 66.67% 151213 chef-client 5 1770000 240000 86.44% 151822 scribe-dispatch 12 15000 0 100.00% 123386 mysqld 5 5000 0 100.00% [...]
列说明:
CPU:执行该进程的 CPU 核心。REFERENCE:访问缓存的总次数(缓存引用)。MISS:缓存未命中的次数。HIT%:缓存命中率,表示成功访问缓存的比例。
关于Linux性能调优之使用BPF工具监控CPU性能指标就和小伙伴们分享到这里
博文部分内容参考 © 文中涉及参考链接内容版权归原作者所有,如有侵权请告知 :)
《BPF Performance Tools》
© 2018-至今 liruilonger@gmail.com , 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)