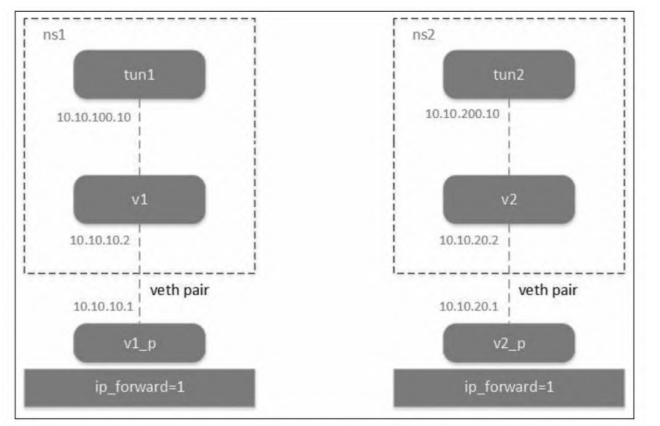
这里我们用两个 Linux network namespace 来模拟 ,创建两个网络命名空间,同时配置两个 veth pair,一端放到命名空间
1 2 3 4
liruilonger@cloudshell:~$ sudo ip netns add ns1 liruilonger@cloudshell:~$ sudo ip netns add ns2 liruilonger@cloudshell:~$ sudo ip link add v1 netns ns1 type veth peer name v1-P liruilonger@cloudshell:~$ sudo ip link add v2 netns ns2 type veth peer name v2-P
确认创建的 veth pair
1 2 3 4 5 6 7 8 9 10 11 12 13
liruilonger@cloudshell:~$ ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: eth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 0a:10:50:88:eb:09 brd ff:ff:ff:ff:ff:ff link-netnsid 0 3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default link/ether 02:42:f9:2d:29:3e brd ff:ff:ff:ff:ff:ff 4: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0 5: v1-P@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 76:81:b0:33:e4:2b brd ff:ff:ff:ff:ff:ff link-netns ns1 6: v2-P@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether aa:a6:ac:15:b1:64 brd ff:ff:ff:ff:ff:ff link-netns ns2
另一端放到 根网络命名空间,同时两个Veth-pair 配置不同网段IP启动。
1 2 3 4
liruilonger@cloudshell:~$ sudo ip addr add 10.10.10.1/24 dev v1-P liruilonger@cloudshell:~$ sudo ip link set v1-P up liruilonger@cloudshell:~$ sudo ip addr add 10.10.20.1/24 dev v2-P liruilonger@cloudshell:~$ sudo ip link set v2-P up
命名空间一端的同样配置IP 并启用
1 2 3 4
liruilonger@cloudshell:~$ sudo ip netns exec ns1 ip addr add 10.10.10.2/24 dev v1 liruilonger@cloudshell:~$ sudo ip netns exec ns2 ip addr add 10.10.20.2/24 dev v2 liruilonger@cloudshell:~$ sudo ip netns exec ns1 ip link set v1 up liruilonger@cloudshell:~$ sudo ip netns exec ns2 ip link set v2 up
确定设备在线
1 2 3 4 5 6 7 8 9 10 11 12 13 14
liruilonger@cloudshell:~$ ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: eth0@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 0a:10:50:88:eb:09 brd ff:ff:ff:ff:ff:ff link-netnsid 0 3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default link/ether 02:42:f9:2d:29:3e brd ff:ff:ff:ff:ff:ff 4: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0 5: v1-P@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 76:81:b0:33:e4:2b brd ff:ff:ff:ff:ff:ff link-netns ns1 6: v2-P@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether aa:a6:ac:15:b1:64 brd ff:ff:ff:ff:ff:ff link-netns ns2 liruilonger@cloudshell:~$
设置隧道端点,用remote和local表示隧道外层IP: remote 10.10.20.2 local 10.10.10.2
隧道内层IP配置: ip addr add 10.10.100.10 peer 10.10.200.10 dev tunl
1 2 3 4
liruilonger@cloudshell:~$ sudo ip netns exec ns1 ip tunnel add tunl mode ipip remote 10.10.20.2 local 10.10.10.2 liruilonger@cloudshell:~$ sudo ip netns exec ns1 ip link set tunl up liruilonger@cloudshell:~$ sudo ip netns exec ns1 ip addr add 10.10.100.10 peer 10.10.200.10 dev tunl liruilonger@cloudshell:~$
原始的IP 头
src: 10.10.100.10
dst: 10.10.200.10
封装后的IP头
src: 10.10.10.2 | src: 10.10.100.10
dst: 10.10.20.2 | dst: 10.10.200.10
同样需要在 ns2 上做相同的配置
1 2 3 4
liruilonger@cloudshell:~$ sudo ip netns exec ns2 ip tunnel add tunr mode ipip remote 10.10.10.2 local 10.10.20.2 liruilonger@cloudshell:~$ sudo ip netns exec ns2 ip link set tunr up liruilonger@cloudshell:~$ sudo ip netns exec ns2 ip addr add 10.10.200.10 peer 10.10.100.10 dev tunr liruilonger@cloudshell:~$
到这里 两个 tun 设备的 隧道就建立成功了,我们可以在其中一个命名空间对另一个命名空间的 tun 设备发起 ping 测试
1 2 3 4 5 6 7 8 9 10
liruilonger@cloudshell:~$ sudo ip netns exec ns1 ping 10.10.200.10 -c 3 PING 10.10.200.10 (10.10.200.10) 56(84) bytes of data. 64 bytes from 10.10.200.10: icmp_seq=1 ttl=64 time=0.091 ms 64 bytes from 10.10.200.10: icmp_seq=2 ttl=64 time=0.062 ms 64 bytes from 10.10.200.10: icmp_seq=3 ttl=64 time=0.067 ms
liruilonger@cloudshell:~$ sudo ip netns exec ns1 ip link 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0 3: v1@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 72:de:67:0b:28:e1 brd ff:ff:ff:ff:ff:ff link-netnsid 0 4: tunl@NONE: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/ipip 10.10.10.2 peer 10.10.20.2 liruilonger@cloudshell:~$
两个命名空间除了 veth-pair 对应的 veth 虚拟设备,各有个一个 tun 设备,link/ipip 中的内容表示封装后的包的两端地址,即外层IP。
1 2 3 4 5 6 7 8 9 10
liruilonger@cloudshell:~$ sudo ip netns exec ns2 ip link 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0 3: v2@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether f2:dd:3c:7d:eb:50 brd ff:ff:ff:ff:ff:ff link-netnsid 0 4: tunr@NONE: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/ipip 10.10.20.2 peer 10.10.10.2 liruilonger@cloudshell:~$