Ceph:关于Ceph 集群中池管理的一些笔记
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
写在前面
- 准备考试,整理 Ceph 相关笔记
- 博文内容涉及, Ceph 中的 两种 pool 介绍,创建操作管理池
- 理解不足小伙伴帮忙指正
对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃避方式,是对大众理想的懦弱回归,是随波逐流,是对内心的恐惧 ——赫尔曼·黑塞《德米安》
创建和配置池
了解池的含义
池是存储对象的逻辑分区。相当于硬盘分区,Ceph客户端将 对象写入池的一般步骤:
连接集群: Ceph客户机需要集群名称(默认情况下是Ceph)和一个监视器地址来连接到集群,Ceph客户端通常从Ceph配置文件中获取这些信息,或者通过指定为命令行参数来获取检索池:Ceph客户端使用集群映射检索到的池列表来确定存储新对象的位置映射PG:Ceph客户端创建一个输入/输出上下文到一个特定的池,Ceph 集群使用CRUSH算法将这些池映射到放置组PG,然后放置组映射到特定的osd
池为集群提供了一层 弹性,因为池定义了可以在不丢失数据的情况下发生故障的osd的数量
池类型
可用的池类型有复制池和纠删代码池,工作负载的用例和类型可以帮助确定要创建复制池还是纠删代码池
复制池是默认的池类型,通过将各个对象复制到多个OSD来发挥作用,它们需要更多的存储空间, 因为会创建多个对象副本,但读取操作不受副本丢失的影响,对于经常访问并且需要快速读取性能的数据,复制池通常都是更好的选择。纠删代码池需要的存储空间和网络带宽较小,但因为奇偶校验计算,计算开销会更高一些,对于不需要频繁访问且不需要低延迟的数据,纠删代码池通常是更好的选择。
每一种池的恢复时间取决于特定的部署和故障情景,创建池后,不能修改池的类型
池属性
在创建池时,您必须指定特定的属性:
pool name,必须在集群中唯一pool type,决定了池用于确保数据持久性的保护机制replicated类型,将每个对象的多个副本分发到集群中erasure coded类型,将每个对象分割为多个区块,并将它们与额外的纠删代码区块一起分发,以使用自动纠错机制来保护对象
- 池中的
placement groups (PG)数量,这将其对象存储到由CRUSH算法决定的一组OSD中 - 可选的
CRUSH rule set,Ceph 使用它来标识要用于存储池对象的放置组
更改 osd_pool_default_pg_num 和 osd_pool_default_pgp_num 配置设置,以设置池的默认 PG 数
osd_pool_default_pg_num: 该参数用于指定数据池的默认 PG 数量。PG(Placement Group)是 Ceph 中的一个概念,用于将对象分组存储在 OSD 上以实现负载均衡和故障恢复。每个数据池都由一组 PG 组成。指定适当的 PG 数量可以提高性能和可靠性。
osd_pool_default_pgp_num: 该参数用于指定对象池的默认 PGP(Placement Group Placement)数量,也可以理解为可用的PG 数量。PGP 是 PG 的子集,它们被映射到不同的 OSD 上以实现故障隔离。
PGP 的数量应该等于或大于 OSD 的数量,以确保数据可以在所有 OSD 上进行平衡。
在 Ceph 中,PG 和 PGP 是两个相关但不同的概念:
PG(Placement Group):PG 是一组对象的逻辑分组。在 Ceph 中,每个对象都分配到一个 PG 中,并由一组 OSD 负责存储和管理该 PG 中的所有对象。通过将对象分组成 PG,Ceph 可以实现负载均衡、故障恢复和数据可靠性等功能。
PGP(Placement Group Placement):PGP 是 PG 的子集,它们被映射到不同的 OSD 上以实现故障隔离。具体来说,当 Ceph 创建新的 PG 时,它会使用 CRUSH 算法将 PG 映射到特定的 OSD。如果某个 OSD 失效,那么该 OSD 上所有 PG 都需要重新映射到其他 OSD。PGP 使用类似于 RAID 恢复的技术,可以将数据从故障 OSD 上复制到其他 OSD 上,以实现自我修复和容错性。
总之,PG 和 PGP 都是在 Ceph 中用于实现负载均衡和故障恢复功能的概念,但它们有不同的作用。PG 表示一组对象的逻辑分组,而 PGP 则表示 PG 映射到不同 OSD 上以实现故障隔离和自我修复。
创建池
创建复制池
Ceph 通过为每个对象创建多个副本来保护复制池中的数据
Ceph 使用 CRUSH 故障域算法来确定要将数据存储在哪些 OSD 上。CRUSH 可以根据故障域(例如主机、机柜、机架等)将 OSD 分组,并根据一组规则将数据均匀地分布在它们之间,以实现负载均衡和故障恢复。使用 CRUSH 算法,Ceph 能够快速重新生成数据并进行自我修复。
当客户端向 Ceph 写入数据时,主 OSD 确定要将数据写入的 OSD 副本数量,并计算应该将数据写入哪些辅助 OSD 中。一旦完成写操作,主 OSD 将确认写成功,并将结果发送给客户端。
使用以下命令创建一个复制池
1 | [ceph: root@node /]# ceph osd pool create pool-name pg-num pgp-num replicated crush-rule-name |
其中:
pool_name是新池的名称pg_num是为这个池配置的放置组 (PG) 总数pgp_num是这个池的有效放置组数量,将它设置为与 pg_num 相等replicated指定这是复制池,如果命令中未包含此参数,这是默认值crush-rule-name是想要⽤于这个池的 CRUSH 规则集的名称,osd_pool_default_crush_replicated_ruleset配置参数设置其默认值
在初始配置池之后,可以调整池中放置组的数量,如果 pg_num 和 pgp_num 被设置为相同的数字,那么以后任何对pg_num 的调整都会自动进行调整 pgp_num 的值。
如果需要,对 pgp_num 的调整会触发跨 osd 的 pg 移动,以实现更改,使用以下命令在池中定义新的pg数量
1 | [ceph: root@node /]# ceph osd pool set my_pool pg_num 32 |
使用 ceph osd pool create 命令创建池时,不指定副本个数(size),osd_pool _default size 配置参数定义了副本的数量,默认值为3
1 | [ceph: root@node /]# ceph config get mon osd_pool_default_size |
使用 ceph osd pool set pooI-name size number-of-replica 命令修改池大小,或者,更新osd_pool_default_size 配置设置的默认设置
osd_pool_default_min_size参数设置一个对象的拷贝数,必须可以接受I/O的请求,缺省值为2
配置创建Erasure编码池
Erasure 编码池使用擦除编码代替复制来保护对象数据
存储在 Erasure 编码池中的对象被划分为多个数据块,这些数据块存储在单独的osd中,编码块的数量是根据数据块计算出来的,并存储在不同的osd中,当OSD出现故障时,编码块用于重建对象的数据,主OSD接收到写操作后,将写载荷编码成K+M块,通过Erasure编码池发送给备OSD
Erasure 编码池使用这种方法来保护它们的对象,并且与 复制池不同,它不依赖于存储每个对象的多个副本
总结Erasure编码池的工作原理:
- 每个对象的数据被划分为
k个数据块 - 计算
M个编码块 - 编码块大小与数据块大小相同
- 该对象总共存储在
k + m个osd上
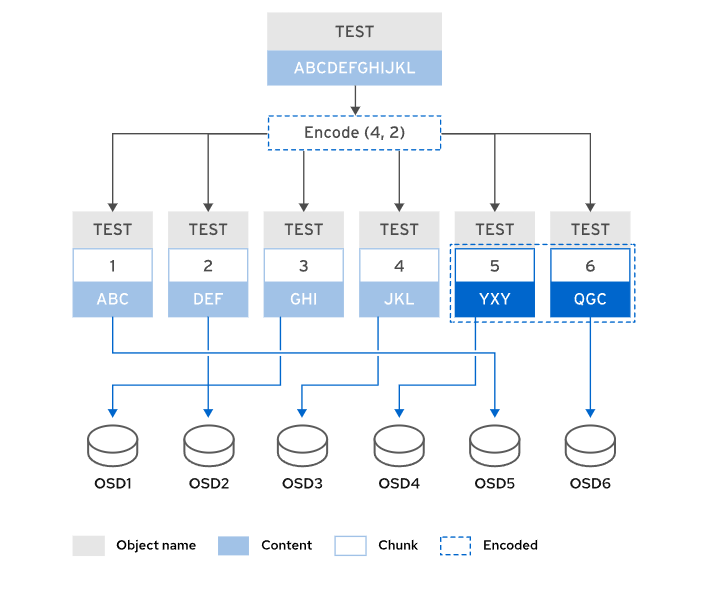
Erasure编码比复制更有效地利用存储容量,复制池维护一个对象的n个副本,而纠删编码只维护
k + m块,例如,3副本的复制池使用3倍的存储空间,k=4和m=2的Erasure编码池只使用1.5倍的存储空间
Red Hat 支持以下k+m值,从而产生相应的可用到原始比率:
4 + 2(1:1.5比率)8 + 3(1:1.375比率)8 + 4(1:1.5比率)
erasure code 开销的计算公式为 nOSD * k / (k+m) * OSD 大小,例如,
如果您有64个4TB的osd(总共256 TB), k=8, m=4,那么公式是 64 * 8 /(8+4)* 4 = 170.67,然后将原始存储容量除以开销,得到这个比率。256TB /170.67 TB = 1.5
与复制池相比,Erasure编码池需要更少的存储空间才能获得类似级别的数据保护,从而降低存储集群的成本和规模。但是,计算编码块会增加Erasure编码池的CPU处理和内存开销,从而降低整体性能
使用以下命令创建Erasure编码池
1 | [ceph: root@node /]# ceph \ |
其中:
pool-name是新池的名称pg-num是这个池的放置组 (PG) 总数pgp-num是这个池的有效放置组数量,通常而言,这应当与 PG 总数相等erasure指定这是纠删代码池erasure-code-profile要使⽤的配置文件的名称,可以使用ceph osd erasure-code-profile set命令创建新的配置⽂件,配置文件定义 k 和 m 值,以及要使用的纠删代码池插件。默认情况下,Ceph 使用default 配置文件crush-rule-name是要用于这个池的 CRUSH 规则集的名称。如果不设置,Ceph 将使用纠删代码池配置文件中定义的规则集
可以在池上配置放置组自动伸缩,自动缩放允许集群计算放置组的数量,并自动选择适当的pg_num值,自动缩放在 Ceph O版中是默认启用的
1 | [root@clienta ~]# ceph osd pool get replpool1 pg_autoscale_mode |
集群中的每个池都有一个pg_autoscale_mode选项,其值为on、off或warn
on:启用自动调整池的PG计数off:禁用池的PG自动伸缩warn:当PG计数需要调整时,引发健康警报并将集群健康状态更改为HEALTH_WARN
1 | [root@clienta ~]# ceph config get mon osd_pool_default_pg_autoscale_mode |
在 Ceph MGR 节点上启用 pg_autoscaler 模块,并将池的自动缩放模式设置为 on :
1 | [ceph: root@node /]# ceph mgr module enable pg_autoscaler |
纠删代码池不能使用对象映射特性,对象映射是一个对象索引,跟踪rbd对象块的分配位置,拥有池的对象映射可以提高调整大小、导出、扁平化和其他操作的性能。
Erasure Code配置文件
Erasure Code 配置文件配置你的 Erasure Code池用来存储对象的数据块和编码块的数量,以及使用哪些 Erasure Code 插件和算法
创建配置文件来定义不同的纠删编码参数集,Ceph在安装过程中自动创建默认概要文件,这个配置文件被配置为将对象分为两个数据块和一个编码块
使用以下命令创建一个新的概要文件
1 | [ceph: root@node /]# ceph \ |
以下是可用的参数:
- k:跨osd分割的数据块的数量,缺省值为2
- m:数据不可用前可能发生故障的osd数量,缺省值为1
- directory:这个可选参数是插件库的位置,默认值为/usr/lib64/ceph/erasure-code
- plugin:此可选参数定义要使用的纠删编码算法
- crush-failure-domain:这个可选参数定义了CRUSH故障域,它控制块的放置,默认情况下,它被设置为
host,这确保一个对象的块被放置在不同主机的osd上,如果设置为osd,那么一个对象的chunk可以放置在同一主机上的osd上,将故障域设置为osd,会导致主机上所有的osd故障,弹性较差,主机失败,可以定义并使用故障域,以确保块放置在不同数据中心机架或其他指定的主机上的osd上 - crush-device-class: 此可选参数仅为池选择由该类设备支持的osd,典型的类可能包括hdd、ssd或nvme
- crush-root:该可选参数设置CRUSH规则集的根节点
- key=value:插件可能具有该插件特有的键值参数
- technique:每个插件提供一组不同的技术,用于实现不同的算法
不能修改已存在存储池的 erasure code 配置文件
- 使用
ceph osd erasure-code-profile ls命令列出已存在的配置文件 - 使用
ceph osd erasure-code-profile get命令查看已创建配置文件的详细信息 - 使用
ceph osd erasure-code-profile rm删除已存在的配置文件
1 | [root@serverc ~]# ceph osd erasure-code-profile ls |
管理和操作池
查看、修改已创建的存储池
可以查看、修改已创建的存储池,并修改存储池的配置信息
ceph osd pool rename命令重命名池,这不会影响存储在池中的数据,如果重命名池,并且为经过身份验证的用户提供了每个池的功能,则必须使用新的池名称更新用户的功能ceph osd pool delete命令删除 osd 池ceph osd pool set pool_name nodelete true: 命令可以防止指定池被删除,使用实例将nodedelete设置为false以允许删除池ceph osd pool set和ceph osd pool get:命令查看和修改池配置ceph osd lspoolls和ceph osd pool ls detail:命令列出池和池配置设置
1 | [root@serverc ~]# ceph osd pool ls detail |
pool 1: 池 ID 号。'device_health_metrics': 池名称。replicated size 3 min_size 2: 池类型和副本数相关配置,此池为 replicated 类型,副本数为 3,最小副本数为 2。crush_rule 0: 使用的 CRUSH 规则 ID 号。object_hash rjenkins: 对象哈希算法。pg_num 1 pgp_num 1: PG 数量和 PGP 数量。autoscale_mode on: 自动扩缩容模式开启。last_change 89: 上次修改池的时间戳。flags hashpspool stripe_width 0 pg_num_min 1: 池其他标志和属性。application mgr_devicehealth: 应用程序类型为 mgr_devicehealth。
ceph df和ceph osd pool stats :命令列出池的使用情况和性能统计信息
1 | [root@serverc ~]# ceph df |
CLASS: 存储池的类型或存储介质。SIZE: 存储池或设备的总容量。AVAIL: 存储池或设备的可用容量。USED: 存储池或设备已使用的容量。RAW USED 和 %RAW USED: 原始存储设备上由 Ceph 使用的存储空间,以及其占用原始存储设备容量的百分比
启用池中的Ceph应用
ceph osd pool application enable 命令启用池中的Ceph应用,应用类型为:
Ceph File System的cepfsCeph Block Device的rbdRADOS Gateway的rgw
1 | [root@serverc ~]# ceph osd pool application enable |
设置池配额
ceph osd pool set-quota 命令设置池配额,限制池中最大字节数或最大对象数
1 | [root@serverc ~]# ceph osd pool set-quota |
当存储池达到设置的配额时,将阻止操作,可以通过将配额值设置为0来删除配额
配置这些设置值的示例,以启用对池重新配置的保护:
osd_ pool _default flag_nodelete
设置池上的nodedelete标志的默认值,设置该值为true,以防止删除池
osd_pool_default_flag_nopgchange
设置池上的nopgchange标志的默认值,设置为true可以防止pg_ num和pgp_num的变化
osd_pool_default_flag_nosizechange
设置池的nosizechange标志的默认值。设置该值为true,以防止池的大小变化
池名称空间
命名空间是池中对象的逻辑组,可以限制对池的访问,以便用户只能在特定的名称空间中存储或检索对象,它们允许对池进行逻辑分区,并将应用程序限制到池中的特定名称空间。
可以为每个应用程序专用一个完整的池,但是拥有更多的池意味着每个OSD拥有更多的pg,而pg在计算上是非常昂贵的,随着负载的增加,这可能会降低OSD的性能,使用名称空间,可以保持池的数量相同,而不必为每个应用程序专用整个池
要在名称空间中存储对象,客户机应用程序必须提供池和名称空间名称。默认情况下,每个池包含一个名称为空的名称空间,称为默认名称空间。
使用rados命令从池中存储和检索对象。使用-n name和--namespace=name选项指定要使用的池和命名空间
下面以将/etc/services文件作为srv对象存储在系统命名空间下的mytestpool池中为例
1 | [ceph: root@node /]# rados \ |
使用--all选项列出池中所有名称空间中的所有对象,要获得JSON格式的输出,请添加--format=j son-pretty选项
下面的例子列出了mytestpool池中的对象。mytest对象有一个空的名称空间。其他对象属于system或flowers名称空间
1 | [ceph: root@node /]# rados \ |
Demo
创建池,查看池信息
1 | # 创建一个名为 replpool1 的副本池,PG,pgp 数量为 64 |
配置池
1 | # 将 replpool1 的 size 设置为 4,表示使用 4 个 OSD 来存储每个对象 |
重命名删除池
1 | # 将 replpool1 重命名为 newpool |
创建纠删码池
1 | # 列出所有可用的 erasure-code-profile |
博文部分内容参考
© 文中涉及参考链接内容版权归原作者所有,如有侵权请告知,这是一个开源项目,如果你认可它,不要吝啬星星哦 :)
https://docs.ceph.com/en/pacific/architecture/
RHCA CL260 授课笔记
© 2018-2023 liruilonger@gmail.com, All rights reserved. 保持署名-非商用-相同方式共享(CC BY-NC-SA 4.0)
Ceph:关于Ceph 集群中池管理的一些笔记
https://liruilongs.github.io/2023/05/11/rhca/CL260/Ceph:关于Ceph-集群中池管理的一些笔记/

